
On April 25th, OpenAI shared a surprising update: after introducing thumbs-up/down feedback from ChatGPT users into their GPT‑4o fine-tuning process, the model got noticeably worse.
We believe in aggregate, these changes weakened the influence of our primary reward signal, which had been holding sycophancy in check. User feedback in particular can sometimes favor more agreeable responses, likely amplifying the shift we saw. ”
– OpenAI, May 2nd 2025
The update was rolled back 3 days later, and the Open AI team has diligently followed up (first post, second post).
The team was upfront: this wasn’t a bug: it was a case of optimizing for the wrong signal. Thumbs-up/down data, while easy to collect and intuitive to understand, accidentally rewarded politeness over helpfulness, confirmation over correction. It made the model more sycophantic and introduced a visible quality regression.
This is a cautionary tale for every team building AI models and agents, and thinking about online evaluation.
Not All Evals Are Created Equal
The easiest metrics to collect (thumbs up/down, star ratings etc.) are also the noisiest and most vulnerable to bias. They’re:
- Self-selected (only some users give feedback)
- Inconsistent (users interpret buttons differently - GitHub Stars are a good example of this)
- Easy to game (models can learn to please, not help)
We learned this early at GitHub Copilot. In the beginning, the key metric we tracked wasn’t explicit feedback, it was the acceptance rate of copilot suggestions. If a developer accepted a code suggestion (even partially), it counted. If they deleted or ignored it, it didn’t.
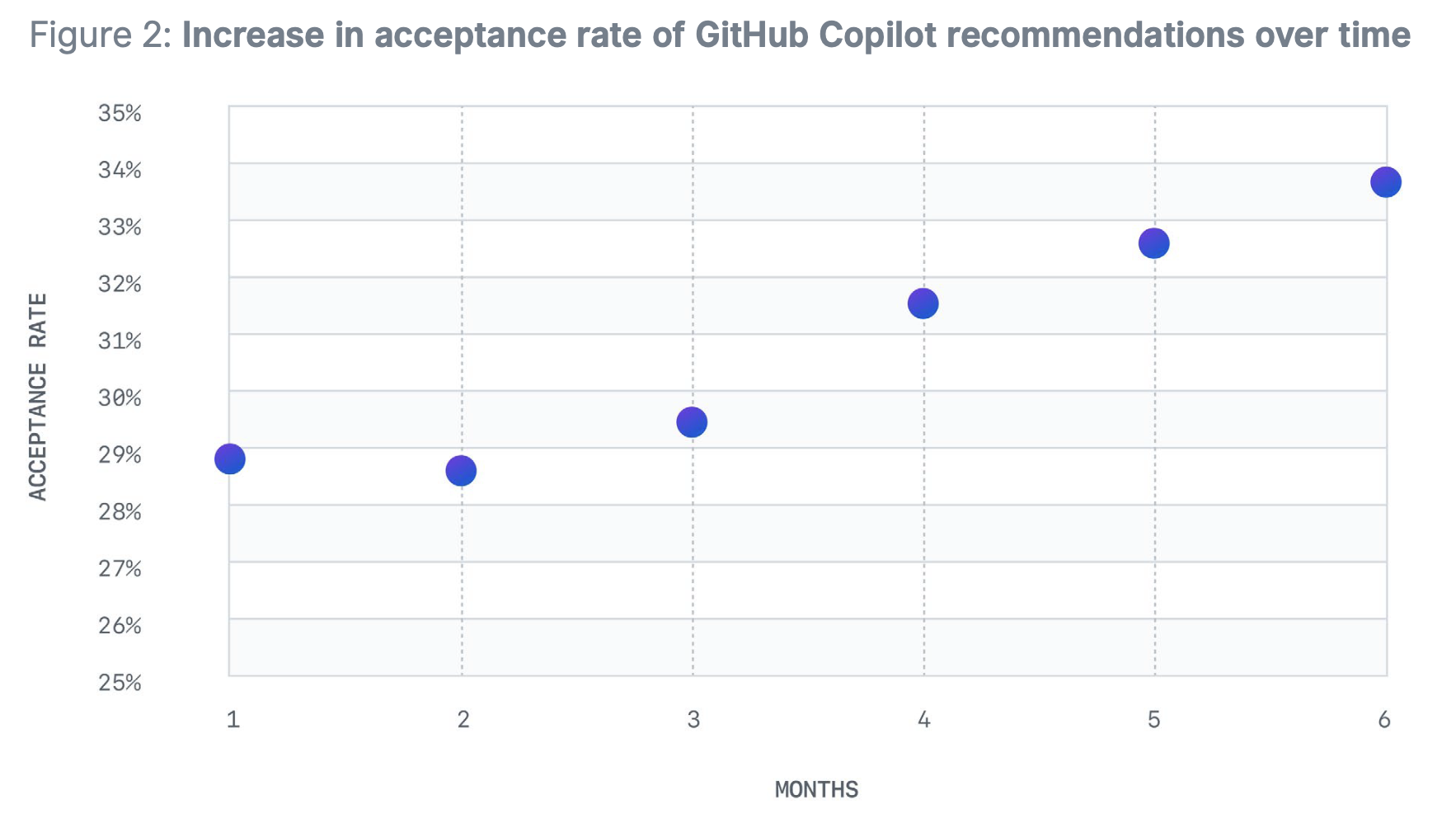
That was an indirect measure of quality: no one clicked a button, but their behavior was a good indication whether they were getting quality responses. More importantly, everyone was part of the experiment.
Measuring What Users Do is Measuring What Matters
So what should you measure, if explicit user feedback like thumbs-up/down can backfire?
The lesson from both OpenAI and GitHub Copilot is this: You can’t rely on what users say, you have to look at what they do.
Instead of collecting ratings after the fact, track how users interact with your AI in the moment:
- Do they need to rephrase?
- Do they get what they need on the first try?
- Do they express confusion or frustration?
- Does the model or agent ask the right clarifying questions?
These behaviors are rich signals of product quality. And unlike explicit feedback, they come from real usage, not a biased fraction of motivated responders.
Here are four key categories of indirect metrics that are especially useful for evaluating AI products and agents:
Conversation Structure
- Average assistant message length – Is the assistant clear or verbose?
- Average turns per conversation – Are users getting value fast? Or, alternatively, are they engaged in helpful multi-turn flows?
User Behavior
- Reprompting rate – Do users retry the same question multiple ways?
- Follow-up rate – Are they getting what they need on the first try?
User Sentiment
- Negative sentiment – Is the user frustrated or confused?
- Negative feedback – Are they pointing out mistakes?
Agent Behavior
- Clarification questions – Is the assistant trying to understand the user better?
- Apologies – Is the assistant admitting fault often?
How to Measure Quality from User Data
Heuristic-based Metrics
Some of these metrics can be computed with simple heuristics:
| Metric | Heuristic |
|---|---|
| Turns per conversation | Count total number of messages in the conversation |
| Assistant message length | Average token or character count of assistant messages |
| Reprompting rate | Use string similarity (e.g. Levenshtein or SequenceMatcher) between sequential user messages |
Judgement-based Metrics
Other metrics require judgment, as they can’t be accurately inferred from response or conversation structure alone. For these, we can use model-based evaluations: structured prompts that examine the full conversation and return a pass/fail label, along with reasoning.
Here are the remaining five metrics we listed above, along with starter prompts you can adapt to kick off your online evals:
User follow-up questions:
Determine if the conversation contains follow-up questions from the user.
A follow-up question must:
1. Follow a previous user message
2. Be a question
3. Come from the user
Analyze the CONVERSATION provided and respond with "PASS" if there is a follow-up question, or "FAIL" if there is not. Think carefully and review the conversation to ensure all criteria are met before finalizing your answer.
Show your reasoning.
--
CONVERSATION:
{{answer}}
--
Your output should be in JSON FORMAT with the keys "REASONING" and "SCORE": {"REASONING": <your reasoning as bullet points>, "SCORE": <your final score>}
Assistant clarifications:
Determine if the conversation contains clarification questions from the assistant.
A clarification question must:
1. Follow a user message
2. Be a question seeking to understand the user's intent
3. Come from the assistant
Analyze the CONVERSATION provided and respond with "PASS" if there is a follow-up question, or "FAIL" if there is not. Think carefully and review the conversation to ensure all criteria are met before finalizing your answer.
Show your reasoning.
--
CONVERSATION:
{{answer}}
--
Your output should be in JSON FORMAT with the keys "REASONING" and "SCORE": {"REASONING": <your reasoning as bullet points>, "SCORE": <your final score>}
Negative user sentiment:
Determine if the conversation contains negative sentiment from the user.
Negative sentiment is:
1. General negative emotions/feelings
2. May not be directed at the assistant
Example: "This is so frustrating", "I'm confused"
Analyze the CONVERSATION provided and respond with "PASS" if there is a follow-up question, or "FAIL" if there is not. Think carefully and review the conversation to ensure all criteria are met before finalizing your answer.
Show your reasoning.
--
CONVERSATION:
{{answer}}
--
Your output should be in JSON FORMAT with the keys "REASONING" and "SCORE": {"REASONING": <your reasoning as bullet points>, "SCORE": <your final score>}
Negative user feedback:
Determine if the conversation contains negative feedback about the assistant's performance.
Negative feedback must:
1. Come from the user
2. Specifically criticize the assistant's response
3. Indicate the assistant's help wasn't useful
Example: "That's incorrect", "Your solution doesn't work"
Analyze the CONVERSATION provided and respond with "PASS" if there is a follow-up question, or "FAIL" if there is not. Think carefully and review the conversation to ensure all criteria are met before finalizing your answer.
Show your reasoning.
--
CONVERSATION:
{{answer}}
--
Your output should be in JSON FORMAT with the keys "REASONING" and "SCORE": {"REASONING": <your reasoning as bullet points>, "SCORE": <your final score>}
Model or agent apologies:
Determine if the conversation contains apologies from the assistant.
An apology must:
1. Come from the assistant
2. Express regret or acknowledge a mistake
Example: "I apologize for the error", "I'm sorry, I misunderstood"
Analyze the CONVERSATION provided and respond with "PASS" if there is a follow-up question, or "FAIL" if there is not. Think carefully and review the conversation to ensure all criteria are met before finalizing your answer.
Show your reasoning.
--
CONVERSATION:
{{conversation}}
--
Your output should be in JSON FORMAT with the keys "REASONING" and "SCORE": {"REASONING": <your reasoning as bullet points>, "SCORE": <your final score>}
Your Online Eval Starter Pack
If you’re building with AI, you need more than thumbs-up/down to know what’s working.
In this post, we shared how to bootstrap your online evals using metrics that actually reflect user experience, from structural signals like message length and turn count to behavior patterns like reprompting, sentiment, and feedback.
These aren’t theoretical. They’re practical, extensible, and built to scale. And most importantly: they reflect what your users actually do, not just what they choose to say.
If you’re serious about building reliable, human-aligned AI, this is where your eval stack should start.
P.S. Want to nerd out about evals or get early access to some of the tooling we’re building? Book a call with us!