
Abstract
Evaluating large language model (LLM) outputs efficiently and accurately – especially for domain-specific tasks – remains a significant challenge in AI development. We present Subject-Matter Expert Language Liaison (SMELL), a novel framework that combines human expertise with LLM capabilities to automatically create feedback-informed LLM judges. SMELL addresses the limitations of generic LLM judges while maintaining scalability through a four-stage pipeline: data annotation by human experts, feedback synthesis, rubric generation, and evaluation using the generated rubric.
Our experiments demonstrate SMELL’s effectiveness across various datasets, achieving high performance with a small number of labeled data points. These results validate the model’s robustness and its ability to efficiently align with human preferences. SMELL offers a powerful, flexible approach to LLM evaluation that can be tailored to specific use cases, potentially revolutionizing how we assess and improve AI language models.
Introduction
The evaluation of large language model (LLM) outputs presents a significant challenge in AI development, particularly when it comes to aligning with human preferences across diverse domains and use-cases. Traditional evaluation methods often fall short in this regard, failing to capture the nuanced judgments that humans apply in different contexts.
A critical shortcoming of existing evaluation approaches is their inability to effectively correlate with human preferences, especially when dealing with domain-specific tasks. Human preferences can vary significantly based on the field of application, the specific use-case, and even cultural or professional contexts. This variability poses a substantial challenge for static or one-size-fits-all evaluation methods.
The Subject-Matter Expert Language Liaison (SMELL) framework addresses these limitations by placing human expertise at the core of the evaluation process. SMELL’s key innovation lies in its ability to scale up from a small subset of human-provided feedback, effectively replicating human preferences across larger datasets. This approach leverages human expertise to define domain-specific success criteria, ensuring evaluations align with nuanced, real-world standards of quality.
By combining human expertise with LLM capabilities, SMELL enables the creation of tailored rubrics that capture domain-specific evaluation criteria. These rubrics are not what you can get off-the-shelf; instead, they are custom generated based on synthesized human feedback, allowing them to adapt to the unique requirements of different use-cases and human preferences. This flexibility ensures that the evaluation process remains aligned with human judgments.
Subject-Matter Expert Language Liaison (SMELL)
We’ve developed Subject-Matter Expert Language Liaison (SMELL), a novel framework that combines human expertise with LLM capabilities to automatically create feedback-informed LLM judges. Our work was inspired by Databricks’ Grading Notes framework, which successfully enhanced LLM evaluation in specialized domains by incorporating concise, task-specific grading guidelines to improve alignment with human preferences (Liu, Zaharia, and Datta, 2024). By generating and refining judge LLM rubrics based on human feedback, we created an adaptive, nuanced, and scalable evaluation system that is representative of human assessments.
Our system is built on a four-stage pipeline:
Data Annotation: Human experts review and provide feedback on a sample of LLM-generated outputs, capturing nuanced human judgments.
Feedback Synthesis: Given a description of the overall task and the annotated data, an LLM analyzes and distills the collective human feedback, identifying patterns and key insights.
Example:
Rubric Generation: Based on the synthesized feedback and the task description, we generate a comprehensive, custom evaluation rubric for judge LLMs.
Example:
Evaluation: The generated rubric is applied by a judge LLM to evaluate new model completions with binary labels, producing consistent, human-aligned assessments at scale
Note: We use GPT-4-turbo with the temperature set to 0.1 for the Feedback Synthesis step, and a temperature of 0 for the Rubric Generation and Evaluation steps. All other parameters are set to the defaults.
Quick detour: What is a judge LLM and how does it work?
One promising approach in evaluation that has gained traction is the concept of "LLM-as-a-judge," where we use one LLM to evaluate the outputs of another. This method leverages the language understanding capabilities of LLMs to provide nuanced, context-aware evaluations. In the LLM-as-a-judge paradigm, we prompt an LLM (the "judge") to evaluate the quality, correctness, or appropriateness of text generated by another LLM. This approach can be more scalable than traditional human evaluation, especially for large datasets, and more flexible than heuristic-based evaluators.
A common implementation of judge LLMs is rubrics – structured prompts that guide their evaluation process. Rubrics can include:
1. Evaluation criteria: The specific aspects of the output to be assessed.
2. Scoring guidelines: How to rate or score each criterion.
3. Examples: Illustrations of high-quality and low-quality responses.
Experimental Set-Up
To test SMELL, we conducted 3 different experiments:
- Ran SMELL against 3 different datasets (
UltraFeedback,Natural-QA,DialogSum) to compare quality by domain / use-case:UltraFeedback:a large-scale dataset with 64k prompts and 256k samples, annotated by GPT-4 across instruction-following, truthfulness, honesty, and helpfulness, used for training reward and critic models. We created a binarized version of this dataset, extracting the reasoning fields for feedback, and labeling responses with scores above 8 as “good” and those with scores of 5 or below as “bad”.Natural-QA:a question-answering dataset from Google, featuring real user queries paired with Wikipedia documents, used to train models for long-form document-based comprehension. We randomly sampled 100 data points and manually provided labels and feedbackDialogSum:a dialogue summarization dataset containing various conversations paired with concise summaries, used to train models for summarizing natural dialogues. We randomly sampled 100 data points and manually provided labels and feedback.
- Ran SMELL against varying amounts of critical feedback for each of the 3 datasets (2, 5, 10, 15, 25, 35, 50, 75, and 100 points of feedback)
- Ran SMELL against different styles of feedback (created 4 variations off of
UltraFeedback):- incomplete sentences (e.g. “Not comprehensive”)
- single sentence summary (e.g. “The response provides a Python function to calculate point C but fails to fully address the multi-step geometric reasoning or ensure that point C is equidistant from A and B as required by the prompt.”)
- 4 words max (e.g. “Lacks comprehensive explanation”)
- overly verbose (e.g. “The response, while adeptly handling the coding aspect, slightly glosses over the geometric reasoning involved, particularly the proof that the sum of angles ∠A and ∠B equals 180° when ∠ACB is at 90° in the context of a parallelogram. This geometric exploration is crucial for a holistic understanding of the problem and warrants a more detailed exposition to satisfy both the mathematical and programming dimensions of the prompt.\n\nFurthermore, [..].”)
To evaluate SMELL’s alignment with human labels, we use Cohen’s Kappa, accuracy, and F1 scores. For each dataset, we sampled an equal number of positive and negative labels and created an 80-20 in-sample / out-of-sample split.
Results & Discussion
Overall Performance
The SMELL evaluator demonstrated strong performance across the three datasets, with particularly notable results on the UltraFeedback dataset.
For UltraFeedback, SMELL achieved a maximum out-of-sample Cohen’s Kappa of 0.92, accuracy of 0.96, and F1 score of 0.96. These high metrics indicate substantial agreement with human judgments and strong predictive power. Importantly, SMELL achieved these results using only 5 in-sample data points with feedback, showcasing its efficiency in learning from limited examples. Notably, the UltraFeedback dataset provided both positive and critical points in its feedback for “bad” labeled data points, while the other two datasets provided only critical feedback.
For Natural-QA and DialogSum, SMELL maintained about 70% agreement with human labels. The lower Cohen’s Kappa scores for these datasets may be partly due to their smaller sample sizes and exclusively critical feedback. The Natural-QA dataset posed additional challenges with its context-dependent question-answering format, yet SMELL’s performance remained stable. SMELL constructs rubrics based solely on input and response, without access to external knowledge or full context. This means that the generated rubrics lack the ability to account for context-dependent information, restricting the judge’s ability to adapt and learn from feedback in cases where context is crucial for evaluation.
Effect of Feedback Quantity
To assess the impact of feedback quantity, we analyzed SMELL’s performance using varying numbers of in-sample data points. We used a random, label-stratified sample from the in-sample set for this analysis. The results, illustrated in the figure below, show SMELL’s human-alignment metrics for the UltraFeedback dataset. The in-sample line represents SMELL’s performance on the varying-sized in-sample sets, while the out-of-sample line shows performance on the constant-sized hold-out set.
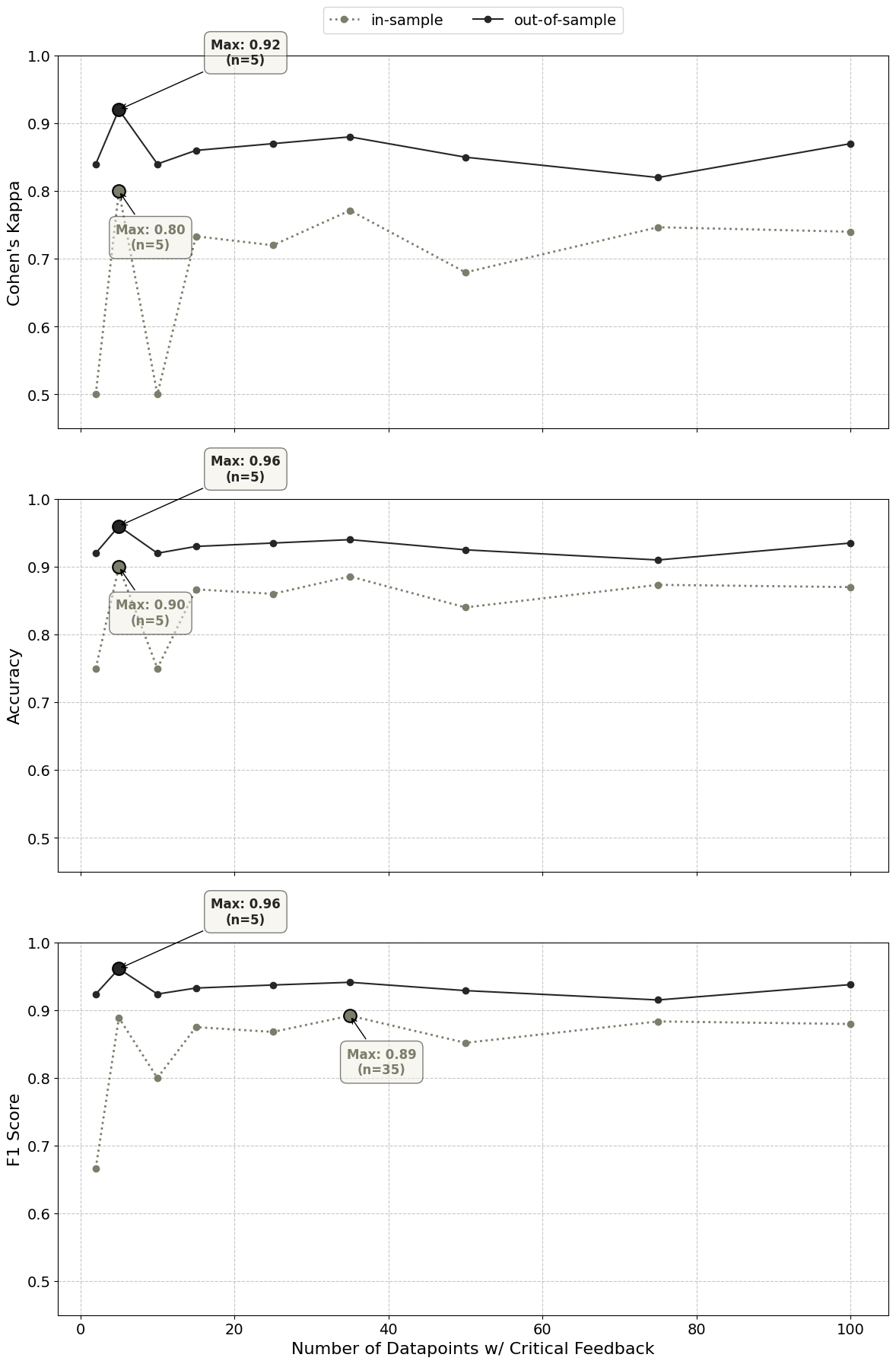 Figure 1: The impact of feedback quantity on the human-alignment metrics for the UltraFeedback dataset.
Figure 1: The impact of feedback quantity on the human-alignment metrics for the UltraFeedback dataset.
The table below shows the full results of the experiment against all three datasets.
| # Critical Feedback | CK (UltraFeedback) | Acc (UltraFeedback) | F1 (UltraFeedback) | CK (Natural-QA) | Acc (Natural-QA) | F1 (Natural-QA) | CK (DialogSum) | Acc (DialogSum) | F1 (DialogSum) |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 0.84 | 0.92 | 0.92 | 0.22 | 0.60 | 0.64 | 0.38 | 0.70 | 0.75 |
| 5 | 0.92 | 0.96 | 0.96 | 0.18 | 0.60 | 0.67 | 0.20 | 0.55 | 0.53 |
| 10 | 0.84 | 0.92 | 0.92 | 0.18 | 0.60 | 0.67 | 0.07 | 0.45 | 0.35 |
| 15 | 0.86 | 0.93 | 0.93 | 0.22 | 0.60 | 0.64 | -0.10 | 0.30 | 0.00 |
| 25 | 0.87 | 0.94 | 0.94 | 0.34 | 0.70 | 0.77 | 0.11 | 0.45 | 0.27 |
| 35 | 0.88 | 0.94 | 0.94 | - | - | - | 0.27 | 0.60 | 0.60 |
| 50 | 0.85 | 0.93 | 0.93 | - | - | - | - | - | - |
| 75 | 0.82 | 0.91 | 0.92 | - | - | - | - | - | - |
| 100 | 0.87 | 0.94 | 0.94 | - | - | - | - | - | - |
Table 1: The Cohen’s Kappa (CK), Accuracy (Acc), and F1 Scores on the out-of-sample sets for each dataset.
Note: CK = Cohen’s Kappa, Acc = Accuracy. “-” indicates that data is not available for that number of critical feedback instances.
Surprisingly, SMELL achieved strong agreement with human labels with very few labeled data points with feedback. Increasing the number of labels with feedback did not improve human-alignment and sometimes led to decreased performance. This phenomenon likely stems from SMELL’s Feedback Synthesis step, which identifies and summarizes high-level issues in the feedback. Repetitive feedback tends to be distilled into the same overarching issues, adding no new information. As feedback quantity increased, rubrics often became more focused on specific details or problems, potentially reducing generalizability when applied to the out-of-sample set. These findings suggest that providing a small number of diverse feedback examples may be most beneficial for SMELL’s performance.
Effect of Feedback Quality
To evaluate SMELL’s robustness to different feedback styles, we conducted an additional experiment. From the UltraFeedback dataset, 200 data points were randomly sampled, and their feedback was modified using GPT-4-turbo. The feedback was rephrased in four different ways: incomplete sentences, lists of up to 4 words, single sentence summaries, and verbose descriptions. This allowed us to assess SMELL’s performance across various feedback formats.
| Average Metrics | Unmodified | Incomplete Sentences | One Sentence | Max 4 Words | Verbose |
|---|---|---|---|---|---|
| Cohen’s Kappa | 0.86 | 0.85 | 0.88 | 0.85 | 0.86 |
| Accuracy | 0.93 | 0.92 | 0.94 | 0.93 | 0.93 |
| F1 | 0.93 | 0.93 | 0.94 | 0.93 | 0.93 |
Table 2: The Cohen’s Kappa, Accuracy, and F1 Scores on the out-of-sample sets. Each dataset is a version of the UltraFeedback data with varying qualitative styles of feedback. The scores were averaged across all runs with varying in-sample sizes.
The results, shown in the table above, reveal that the ‘one sentence’ feedback variation performed best across all metrics on average. This variation provides the most descriptive feedback while maintaining brevity. Notably, the overly verbose and descriptive feedback did not outperform the unmodified, brief, and non-specific feedback. This indicates that excessive information does not necessarily lead to improved results, aligning with our earlier findings on feedback quantity.
Key Considerations
Below, we have compiled a list of tricks to help you test SMELL on your own data:
- Feedback Quality
The effectiveness of the system is closely tied to the quality of human feedback provided during the annotation phase. It is essential to involve annotators with relevant domain expertise to offer accurate, meaningful evaluations. Our research indicates that the most effective feedback is both clear and concise, ideally not exceeding one sentence. For instance, feedback such as: ‘The response provides a general overview of egg-laying animals but lacks detailed tables and omits a comprehensive analysis of evolutionary advantages and disadvantages’ is preferable to overly verbose feedback.
The goal is to deliver as much informative content as possible in a compact form, capturing essential aspects without unnecessary elaboration. The quality of feedback far outweighs quantity – a small set of diverse examples with concise constructive feedback can be much more effective than a large set of cursory descriptions.
- Look at your data
While the system automates the creation of evaluators, manually inspecting your data remains crucial. Continuously monitor the model’s outputs and make adjustments as necessary to address any anomalies or limitations. Our research shows that this method performs best when applied to datasets that share a common theme (e.g., question answering within a specific domain), as this tends to produce higher-quality feedback structuring. The goal is to create “structured feedback” that is as tailored as possible while maintaining generalizability. Therefore, the data points used for training should be representative of the intended use case to maintain alignment between the evaluation process and real-world applications.
Conclusion
SMELL offers a flexible approach to LLM evaluation that can be tailored to your specific use case. By leveraging both human expertise and LLM capabilities, we can create more accurate, use-case-specific evaluation systems that evolve with your own human assessments.
Additional details about SMELL will be released in an forthcoming paper.
In the meantime, we invite you to try it out yourself with the provided code snippets, and see how SMELL can enhance your development workflow.
If you’re interested in building a custom judge tailored to your specific use case, or if you’d like to contribute to our research, we’d love to collaborate! You can share your datasets with us at research@quotientai.co. We’ll publish results based on the data you provide, with full attribution and recognition of your contributions.
Do your LLMs pass the SMELL test? 👃
Notebook and API access
Want to explore or integrate SMELL into your own ai development workflow? We provide two key resources:
📓 Detailed Notebook: For an in-depth look at the SMELL framework, including implementation details and experimental results, check out our comprehensive Jupyter notebook: 🔗 SMELL Framework Notebook
📂 Example Dataset: Explore a subset of UltraFeedback example dataset on Hugging Face to see the type of data SMELL works with: 🔗 SMELL on Hugging Face
🔗 API Integration: To test out our preview version of SMELL in your projects, refer to our API documentation: 🔗 https://smell.quotientai.co/