
AI agents rely on external tools to handle tasks like updating files, processing data, navigating the web, and much more. Tools also introduce a new layer of complexity and failure modes. Did the agent call the right tool? Did it format the parameters correctly? Did it hallucinate a function that doesn’t exist?
We released limbic-tool-use-0.5B-32K, a new small model purpose-built to assess inaccuracies with tool use in AI agents. Along with open weights for the model, we are also releasing limbic-eval-tool-use-mcp - an open test set for the model.
In this post, we’ll tell you about how to get started with limbic-tool-use-0.5B-32K and how we developed our data curation and training pipeline.
tl;dr: Want to try limbic-tool-use-0.5B-32K?
- Model: Open weights on Hugging Face
- Eval Dataset: Dataset available on Hugging Face
- Try it on Modal: Gist
What does the model do?
limbic-tool-use-0.5B-32K is a lightweight evaluator model that takes in:
- the message history as a list of dict/json objects at the time of the most recent tool call, including the user request and the model tool call response
- the list of tool schemas provided to the model as a list of dict/json objects at the time of the most recent tool call
It generates structured JSON:
{
"score": "correct | incorrect_tool | incorrect_parameter_names | incorrect_parameter_values",
"reason": ["list of failure reasons"]
}
This allows you to automatically detect common tool-use failures:
incorrect_tool: Wrong or hallucinated function nameincorrect_parameter_names: Missing or wrong function parametersincorrect_parameter_values: Wrong parameter values or types
Despite its small size, the model outperforms GPT-4.1 and Claude-Sonnet-4 on a held-out test set of tool call evaluation tasks.
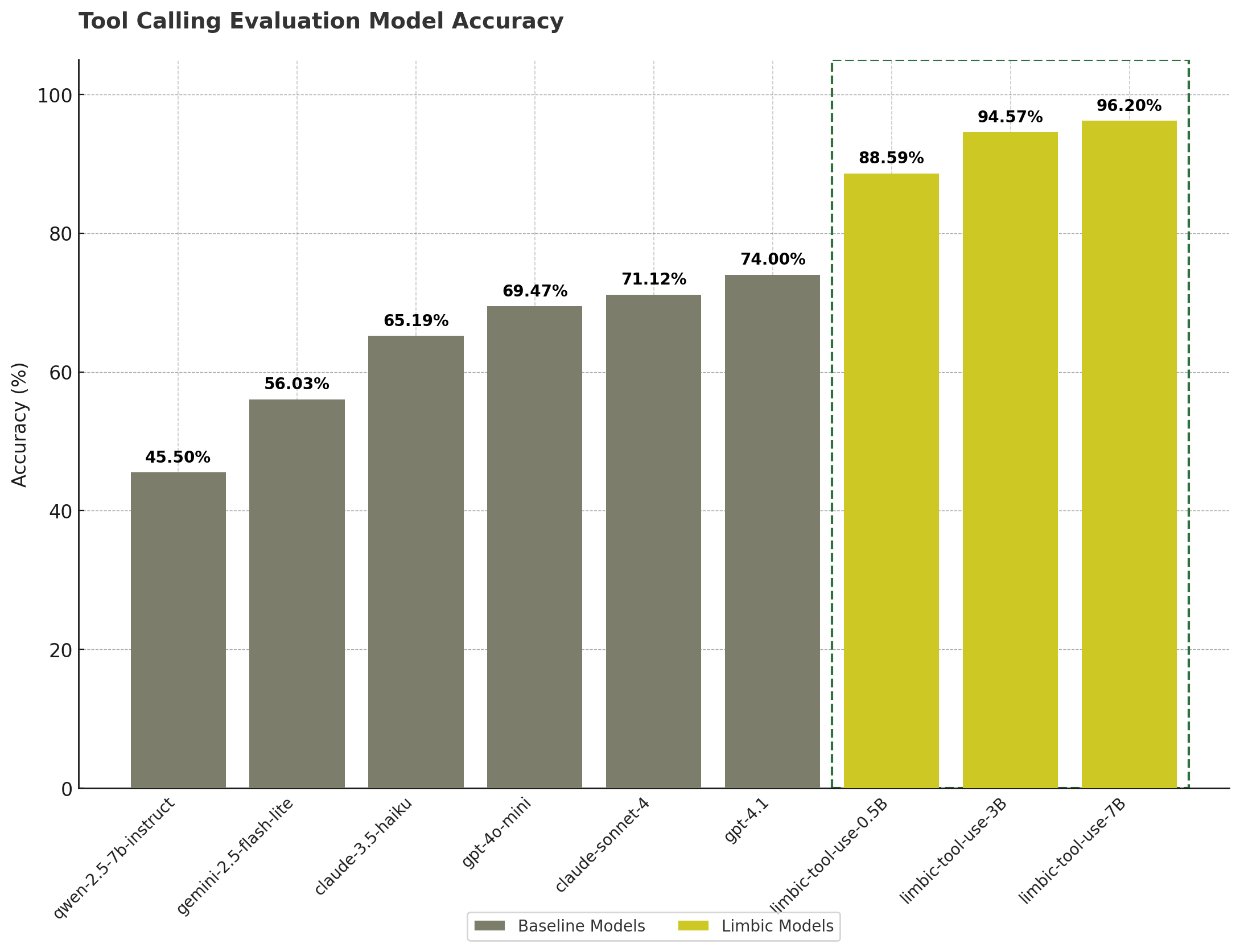
How we made limbic-tool-use-0.5B-32K
How we built the training dataset
We constructed a high-quality dataset from publicly available MCP server tools, using a multi-step data pipeline. The goal was to simulate realistic tool use and create challenging failure cases for the model to learn from.
We settled on achieving the following key features for our training dataset:
Realistic data
Uses actual MCP server definitions and generates realistic usage scenariosComprehensive error coverage
Covers function name, parameter name, and parameter value errorsMultiple formats
Supports various tool calling formats (Anthropic, OpenAI, etc.)Proper splitting
Server-aware splitting prevents data leakageBalanced classes
Stratified sampling ensures representative error distributionsRich metadata
Tracks error strategies, server information, and failure reasons
Our data curation pipeline
1. Data Collection
- Pulled MCP server definitions from the Smithery registry API
- Extracted server metadata and tool specifications
Output: Raw MCP server data with schemas.
2. Data Reformatting
- Transformed from server-centric to tool-centric format
- “Exploded” each server into rows where each row represents a single tool
Output: One row per tool with attached server context.
3. Synthetic Data Generation
- Generated realistic parameter values
- Created natural user prompts aligned with tool usage
- Generated system messages to set conversational context
Output: Synthetic tool usage examples.
4.Ground Truth Creation
- Added a ground_truth_tool_call field to each record
- Constructed the canonical tool call message with correct parameter names and values
Output: Ground truth-aligned data.
5. Data Mixing
- Created variants of each example with different toolset configurations:
- Same-server: 1, 10, or 20 tools
- Cross-server: Tools from 4 or 10 different servers
- Included both ground truth and “no ground truth” versions
Output: Diverse dataset simulating real-world toolset conditions.
6–8. Error Injection Introduced specific types of tool use mistakes as follows:
- Simulated wrong tool calls (e.g. typos, wrong function names, hallucinated tools)
- Introduced issues with parameter naming (e.g. misspellings, synonyms, missing/extra fields)
- Injected incorrect types, invalid structures, and malformed values
Each example includes:
model_tool_call: the erroneous tool callfailure_reason: a description of the error- Metadata about the injection strategy used
9. Training Data Assembly
- Combined correct examples and all error variants into a unified format.
- Standardized columns:
available_tools: full list of tools visible to the agentuser_request: user-generated prompttool_call: model’s generated tool call (correct or incorrect)score: one of correct, incorrect_tool, incorrect_parameter_names, incorrect_parameter_valuesfailure_reason: explanation if the call is incorrectmessage_history: full chat-style context
- Randomized formatting styles across Anthropic, OpenAI, Qwen, and Llama templates
Output: Labeled training dataset with rich metadata.
10. Train/Test Split
- Stage 1: Server-aware split (75%/25%)
Ensured that all examples from a given server are assigned to the same partition to avoid leakage - Stage 2: Stratified validation split (90%/10%)
Preserved distribution of scores (correct, incorrect_*) across training and validation sets
Output: Final train, validation, and test splits ready for fine-tuning and benchmarking.
The result is a robust, well-structured dataset for training and evaluating models on tool use accuracy in multi-tool agent environments.
In total, we trained the model using 162 different MCP servers and more than 50 million tokens.
How we fine-tuned limbic-tool-use-0.5B-32K
We fine-tuned using Qwen-2.5-0.5B-Instruct as the base model for limbic-tool-use-0.5B-32K. Internally, we also trained larger 3B and 7B versions using the same pipeline for comparison.
The model was fine-tuned using Unsloth, a lightweight framework designed for efficient LoRA-based training. We applied Low-Rank Adaptation (LoRA) with 4-bit quantization to reduce memory requirements and speed up training without sacrificing performance.
Training was conducted on a single H100 GPU through Modal for all three models, enabling fast iteration with long sequence lengths and large batch sizes.
How we benchmarked limbic-tool-use-0.5B-32K
We benchmarked limbic-tool-use-0.5B-32K against a set of leading general-purpose LLMs—GPT-4.1, Claude, Gemini, and others. To ensure a fair comparison, we used the same exact same evaluation rubric as the fine-tuning script and the same system message for every model. We required them all to return output in the same structured JSON format.
All models were required to return a score field (with one of the four valid labels) and, if incorrect, a reason field with an explanatory list. Different providers were configured to support structured outputs in the following ways:
- OpenAI models were guided with Pydantic schemas to enforce structure.
- Anthropic models used the instructor library for JSON-constrained completions.
- Google’s Gemini model was wrapped with a response schema validator.
- Together.ai models followed a standard chat completion format without enforced structure.
Each model was evaluated on the percentage of correct predictions on valid responses.
This rigorous evaluation protocol allowed us to directly compare the models’ ability to assess tool call correctness.
Benchmark Results
Despite being just 0.5B parameters, limbic-tool-use-0.5B-32K outperforms every foundational model in both accuracy and consistency.
How to use limbic-tool-use-0.5B-32K
You’ll soon be able to run limbic-tool-use-0.5B-32K in a few different ways:
Run It Locally
You can use the model right now:
- Model: Open weights on Hugging Face
- Eval Dataset: Dataset available on Hugging Face
Try it on Modal
Checkout the quickstart guide for evaluating tool calls using a hosted endpoint https://gist.github.com/freddiev4/b17e86eeadd1ae2e4a4a2333a7edcf7e
We provided a minimal example of how to send tool schemas, message history, and tool calls to the hosted evaluator and get back a structured verdict.
This setup is ideal for experimentation, local debugging, or validating your own tool use examples before integrating into a full pipeline.
What’s next
We’re building a new system called Limbic, which captures and processes agent behavior, helps you understand it, and automatically improves your agents for you.
We built limbic-tool-use-0.5B-32K, our first model of the series, to address a critical gap in the agent development stack: finding problems with tool use in AI agents.
Future versions of Limbic will extend beyond tool use to cover other core behaviors—like retrieval accuracy, planning consistency, and multi-step decision making. We’re also working on deeper integrations with the Quotient platform, so you can plug these evaluators directly into your development workflow and in-the-loop of your agents in production.
We’d love your feedback. You can reach out to us directly at research@quotientai.co. Stay tuned for more announcements.
Happy building!