
As large language models (LLMs) are increasingly adopted in critical industries, ensuring their outputs are factually grounded has emerged as a major concern. One prominent issue is “hallucination,” where models generate content unsupported by or contrary to the provided evidence. Existing hallucination detection benchmarks are often limited, synthetic, or narrowly focused on specific tasks like question-answering. Recognizing this gap, we developed HalluMix: a task-agnostic, multi-domain benchmark designed to evaluate hallucination detection in realistic, diverse contexts.
Why HalluMix?
Traditional benchmarks fall short because they rarely capture the complexity of real-world scenarios, where multi-sentence outputs must be evaluated against multi-document contexts. HalluMix addresses this limitation by including examples from various domains (healthcare, law, science, and news) and multiple tasks (summarization, question answering, natural language inference). Each example in HalluMix contains:
Documents: Context represented as a list of shuffled text chunks (e.g., tokenized sentences or paragraph blocks) with random, irrelevant document chunks from unrelated documents. This mimics real-world Retrieval Augmented Generation (RAG) scenarios.
Answer: The hypothesis to be evaluated, such as a summary sentence, answer, or claim.
Hallucination Label: A binary indicator marking whether the response contains a hallucination.
Source Identifier: A label for the original dataset for provenance tracking.
To closely simulate retrieval noise encountered in practical applications, HalluMix introduces distractors into the context of faithful examples, increasing evaluation complexity without compromising data validity.
Building HalluMix
HalluMix integrates high-quality human-curated datasets through careful transformations:
Natural Language Inference (NLI) datasets (sentence-transformers/all-nli, stanfordnlp/snli, snli-hard, GLUE: mnli, rte, wnli) were adapted by mapping “entailment” labels as faithful and “neutral/contradiction” as hallucinated.
Summarization datasets (sentence-transformers/altlex, CNN/DailyMail, DialogSum, XSum, arXiv summarization, GovReport summarization, PubMed summarization) were transformed by mismatching summaries with unrelated documents to generate hallucinated instances.
Question Answering (QA) datasets (SQuAD-v2, DROP, Databricks-Dolly-15K, PubMedQA, NarrativeQA) included context-answer mismatches, LLM-generated plausible but incorrect answers, and converted single-word answers into declarative sentences to ensure realism.
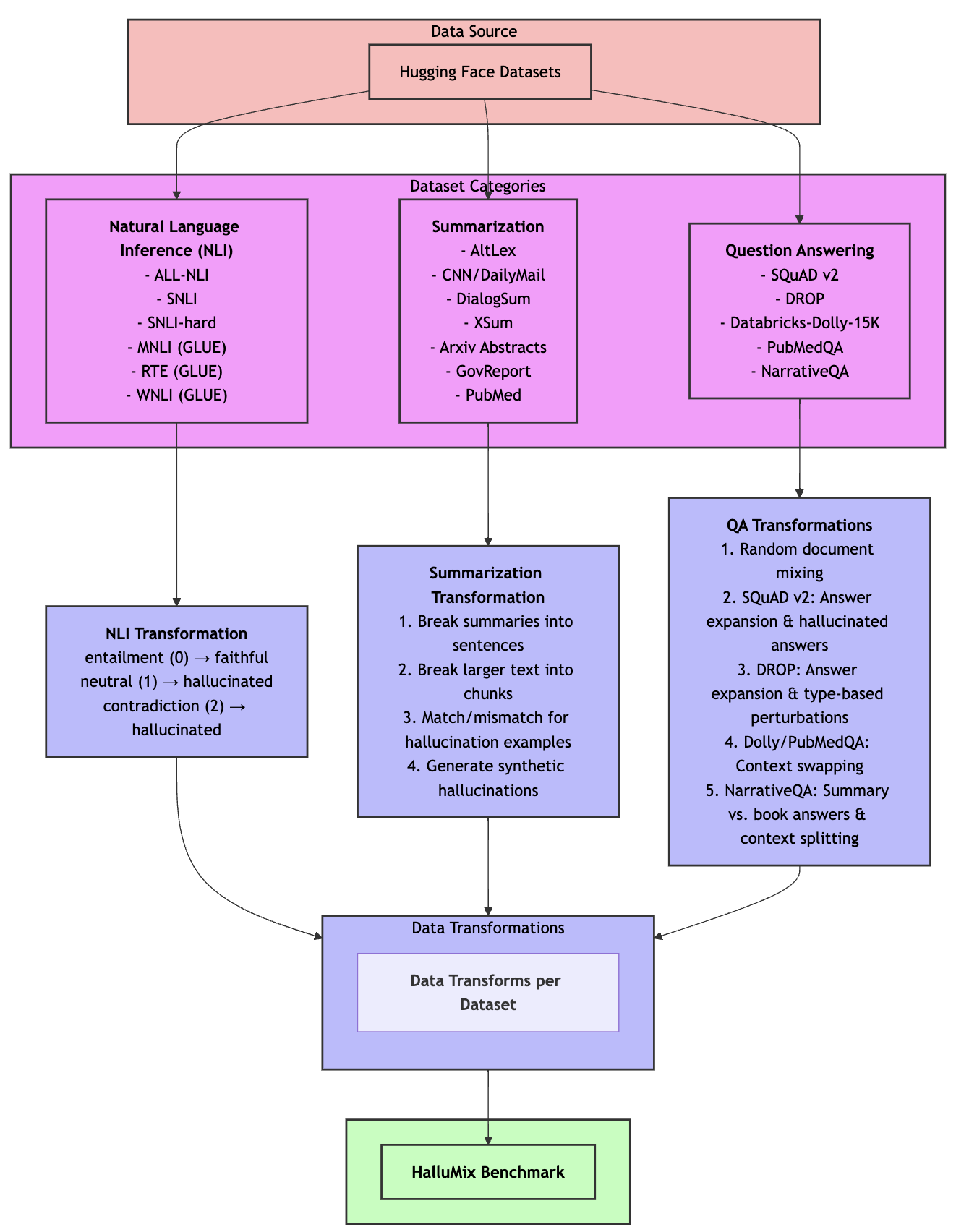
This rigorous methodology resulted in a balanced, diverse dataset of 6,500 examples across multiple tasks and domains, enabling broad and robust evaluation. The dataset is publicly available on Hugging Face.
Evaluating Detection Systems with HalluMix
Using HalluMix, we evaluated seven leading hallucination detection systems, both open- and closed-source, revealing significant insights:
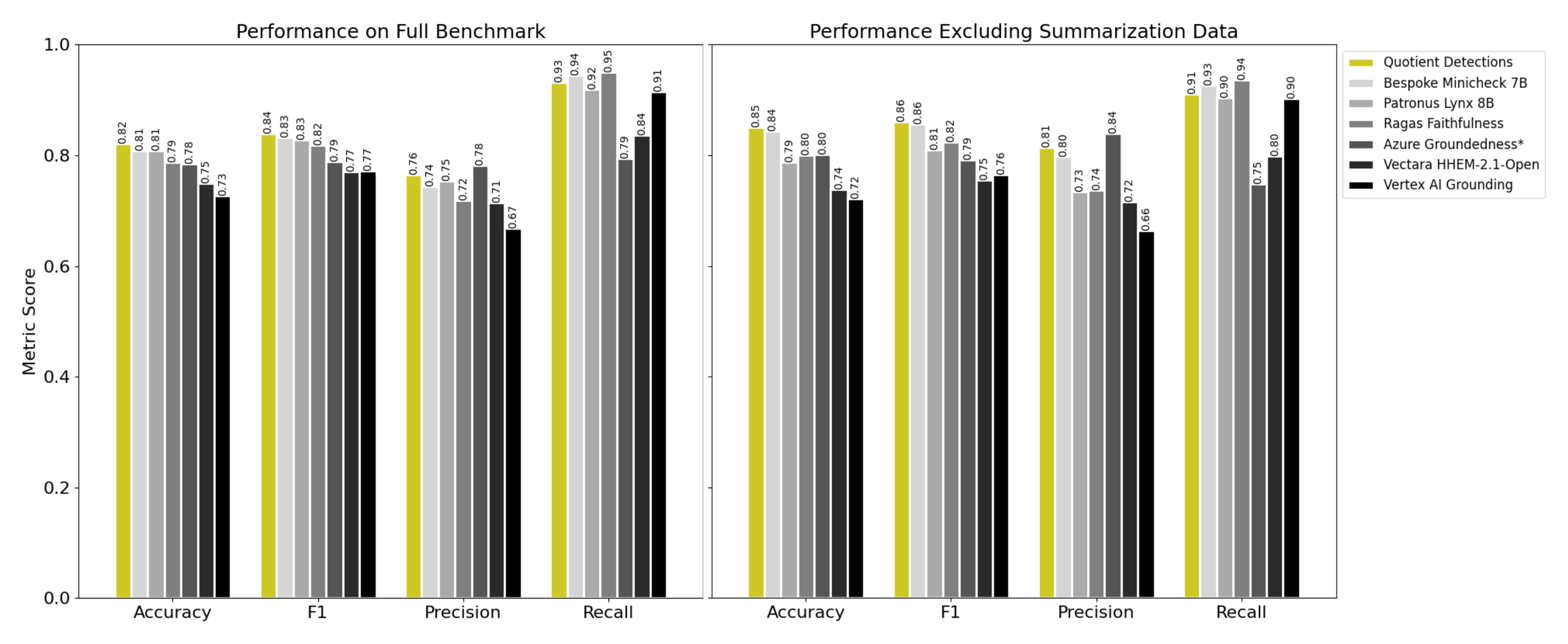
Quotient Detections achieved the best overall performance (Accuracy: 0.82, F1 score: 0.84), showing balanced precision and recall.
Azure Groundedness demonstrated high precision but lower recall, whereas Ragas Faithfulness had high recall at the expense of precision.
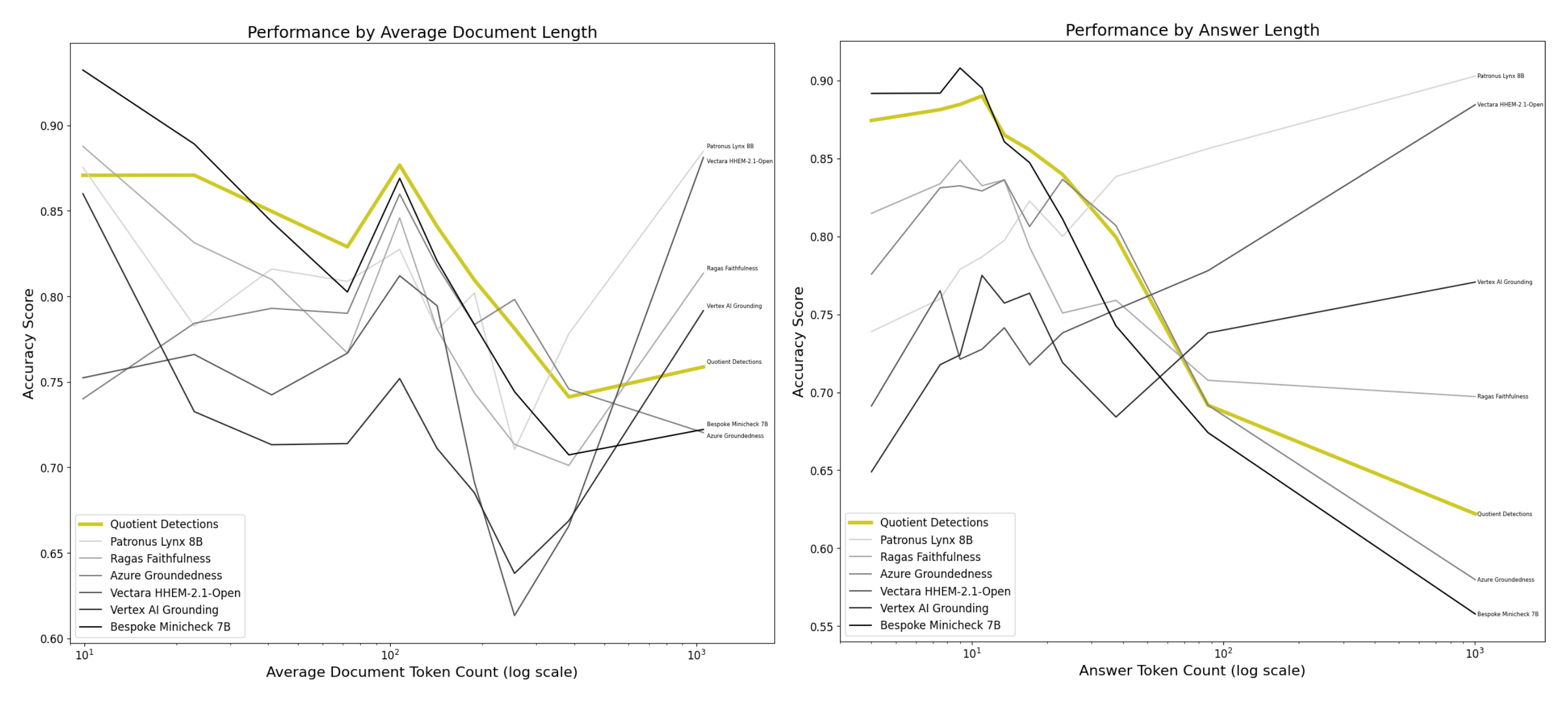
- System performance varied notably with content length and task type. Models fine-tuned on long contexts (e.g., Patronus Lynx 8B) excelled in summarization tasks but faltered on shorter NLI or QA tasks. Conversely, sentence-based detectors (Quotient Detections and Bespoke-Minicheck-7B) performed exceptionally on short contexts but struggled with long-form content.
Key Findings and Implications
Our analysis highlighted several critical takeaways:
Sub-source Overfitting: Some detection systems appear overly tuned to specific datasets, indicating limited generalizability.
Content-Length Challenges: Effective hallucination detection heavily depends on handling context length and preserving inter-sentence coherence.
Architectural Trade-offs: Continuous-context methods offer strong performance on longer texts, whereas sentence-level methods excel at precise short-context detection but lose context in longer documents.
Toward Robust, Real-World Detection
Future research must focus on combining the strengths of both approaches—perhaps through hierarchical or sliding-window contexts—to ensure reliable detection across various input formats and lengths. By openly releasing HalluMix, we hope to encourage further innovation in creating robust hallucination detection tools, critical for deploying trustworthy LLM applications.
With HalluMix, we’re taking an essential step toward addressing one of AI’s most pressing challenges—ensuring factual correctness and trustworthiness in practical deployments.
References
🤗 Dataset: HalluMix Dataset on Hugging Face