
Large language models (LLMs) are increasingly being used to interact with external tools and APIs. However, evaluating their tool calling capabilities presents unique challenges compared to traditional single-turn or retrieval-augmented use cases. This post is an attempt to synthesize our findings from recent papers to help builders effectively evaluate LLM tool calling. We read through and reviewed a dozen papers published between 2023 and 2025 to better understand how tool calling is evaluated.
After reading this, we hope you’ll leave with an understanding of the key considerations in evaluating LLM tool calling and have a mental model to start assessing tool calling capabilities in your own systems.
Key Considerations Before Evaluating Tool Calling
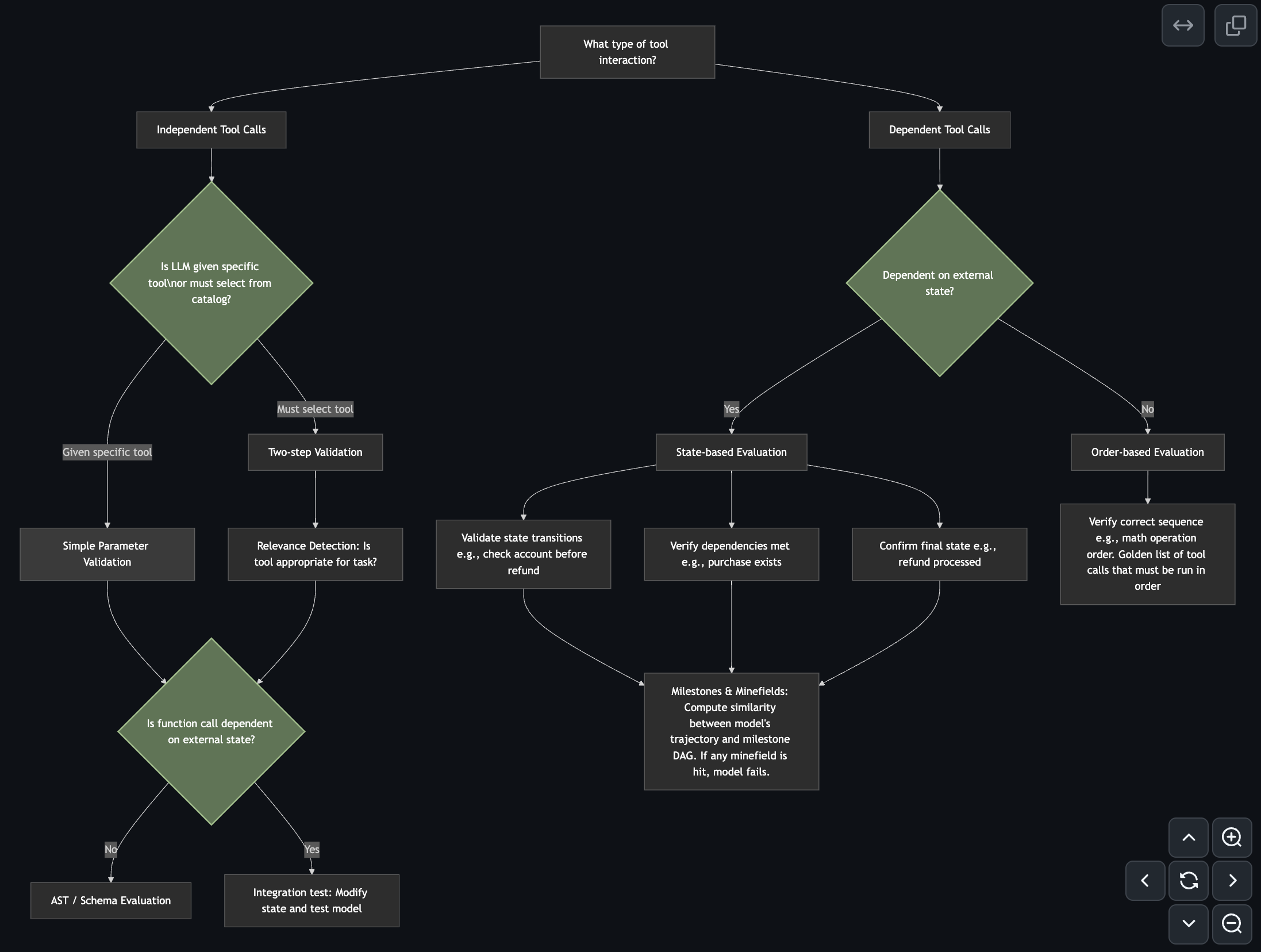
Before diving into specific evaluation approaches, let’s step back and think through a few questions. Answering these upfront will help frame your tool calling evaluation:
What type of tool interaction are you evaluating?
Does the order of operations matter for your system? Are your tools interdependent (where the output of one influences another) or can each tool function independently?
Does your system rely on external state?
Is your tool calling interacting with dynamic external states, such as databases (SQL, CRM, spreadsheets)? For example, in customer support or sales scenarios, database states might change throughout an interaction.
Is your system time-dependent?
Does the tool call depend on time-sensitive information, like news updates, stock prices, or live web data?
What are your evaluation goals?
Common objectives include:
- Parameter correctness: Did the model provide accurate and appropriate parameters for tool invocation?
- Tool selection accuracy: Did the model choose the correct tool for the task?
- State management: Was the state correctly updated or maintained across interactions?
- Error handling: How effectively did the model handle unexpected conditions or failures?
- Task completion: Did the model reach the desired end state successfully?
- Consistency: How important is it that the model consistently uses the same tools for the same tasks, or that the results remain stable across tool invocations?
What validation data do you have?
Depending on your resources, you might have:
- Reference solutions: Expected tools or sequences of tool usage, milestons, etc.
- Ground truth states: Expected system state after tool use.
- Expert annotations: Human-validated examples of correct tool use.
- Automated test suites: Synthetic validation cases.
The validation data you have at hand will influence which evaluation approaches are feasible.
⚠️ These considerations specifically focus on tool calling. We intentionally don’t touch on broader, equally important production concerns like latency, cost, or tolerance for errors like hallucinations etc., as well as separate challenges with evaluating LLM text generation.
Note: we use “tool calling” and “function calling” interchangeably in this post.
Evaluation Approaches
With the above considerations in mind, we’ll go over specific approaches used to evaluate LLM tool calling capabilities from each of these papers:
API-Bank (April 14, 2023)
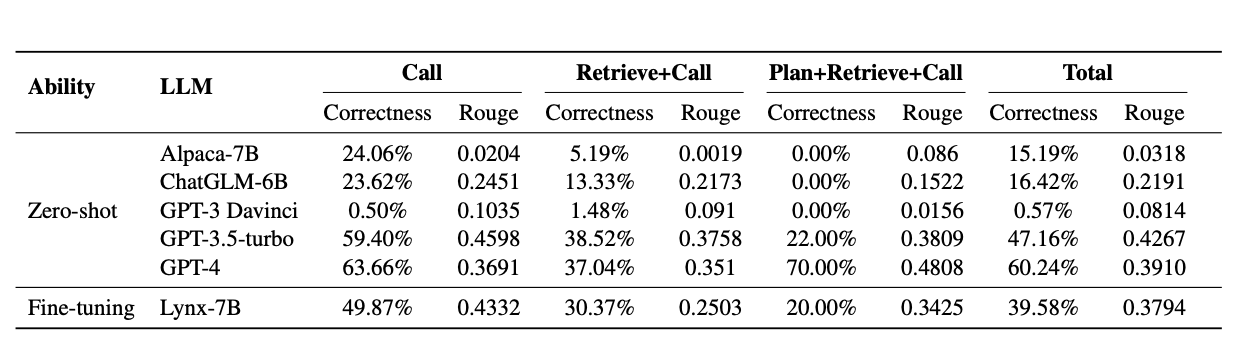
API-Bank breaks down the tool calling problem into three distinct classes:
Call:The model’s ability to invoke a specific API when the API is known. Given a query and a predefined set of tools, the evaluation checks if the correct tool was called compared to a ground-truth tool call.
Retrieval + Call:The model’s ability to retrieve and call the appropriate API when the APIs are not known in advance. The model is given a single predefined search tool, to find other available tools by calculating cosine similarity between the sentence embeddings of the API metadata (tool descriptions) and keywords inferred from the model’s query interpretation. From the top-five suggested tools, the model must select the correct one, validated against the ground-truth tool call.
Plan + Retrieval + Call:The model’s ability to continuously plan, retrieve, and call multiple APIs when the APIs are not known in advance. Instead of giving the model simple queries that require a single tool, they provide more complex queries that require a sequential chain of API calls to complete the task. The evaluation confirms that the model’s final response (derived from the execution of the last API call) matches the ground-truth tool call.
Example of an API-Bank evaluation: Model Input:
User: Can you please modify my appointment scheduled for March 25th with Dr. Kim to March 26th with Dr. Lee?
AI: Sure, I can help you with that. Please provide me with the appointment ID and the new appointment date and doctor's name.
User: The appointment ID is 34567890 and the new date is March 26th with Dr. Lee.
AI: Alright. I'll modify your appointment now.
Generate API Request:
Generate an API request in the format of [ApiName(key1='value1', key2='value2', ...)] based on the previous dialogue context.
The current year is 2023.
Input:
User: User's utterence
AI: AI's response
Expected output:
API-Request: [ApiName(key1='value1', key2='value2', ...)]
API descriptions:
{"name": "QueryHealthData", "description": "This API queries the recorded health data in database of a given user and time span.", "input_parameters": {"user_id": {"type": "str", "description": "The user id of the given user. Cases are ignored."}, "start_time": {"type": "str", "description": "The start time of the time span. Format: %Y-%m-%d %H:%M:%S"}, "end_time": {"type": "str", "description": "The end time of the time span. Format: %Y-%m-%d %H:%M:%S"}}, "output_parameters": {"health_data": {"type": "list", "description": "The health data of the given user and time span."}}}
{"name": "CancelRegistration", "description": "This API cancels the registration of a patient given appointment ID.", "input_parameters": {"appointment_id": {"type": "str", "description": "The ID of appointment."}}, "output_parameters": {"status": {"type": "str", "description": "The status of cancellation."}}}
{"name": "ModifyRegistration", "description": "This API modifies the registration of a patient given appointment ID.", "input_parameters": {"appointment_id": {"type": "str", "description": "The ID of appointment."}, "new_appointment_date": {"type": "str", "description": "The new appointment date. Format: %Y-%m-%d."}, "new_appointment_doctor": {"type": "str", "description": "The new appointment doctor."}}, "output_parameters": {"status": {"type": "str", "description": "The status of modification."}}}
Expected Model Output:
API-Request: [ModifyRegistration(appointment_id='34567890', new_appointment_date='2023-03-26', new_appointment_doctor='Dr. Lee')]
To evaluate each of their examples, they use the following evaluation metrics:
- Accuracy: Calculated as the ratio of correct API calls over total API calls.
ROUGE-L: Used to assess the quality of the model’s final textual response.
ToolTalk (November 15, 2023)
ToolTalk is a dialogue-focused benchmark that evaluates LLM tool calling across different scenarios. Each scenario comprises multiple user requests with corresponding tool calls required to complete tasks, leveraging a predefined set of 28 APIs (e.g., alarms, emails, calendars, messaging, weather services). ToolTalk provides explicit ground-truth references, detailing both the exact tool calls as well as the expected outcomes.
The benchmark provides tool-specific rules for validating correctness due to the constrained API set.
For example, if a scenario requires sending an email to multiple recipients, correctness is determined by verifying recipient email sets rather than enforcing a strict order.
The evaluation process involves breaking conversations into incremental segments, each comprising the current user message and all previous dialogue context. After each user message, the evaluation checks if the subsequent model action (tool invocation or generated response) aligns with expectations.
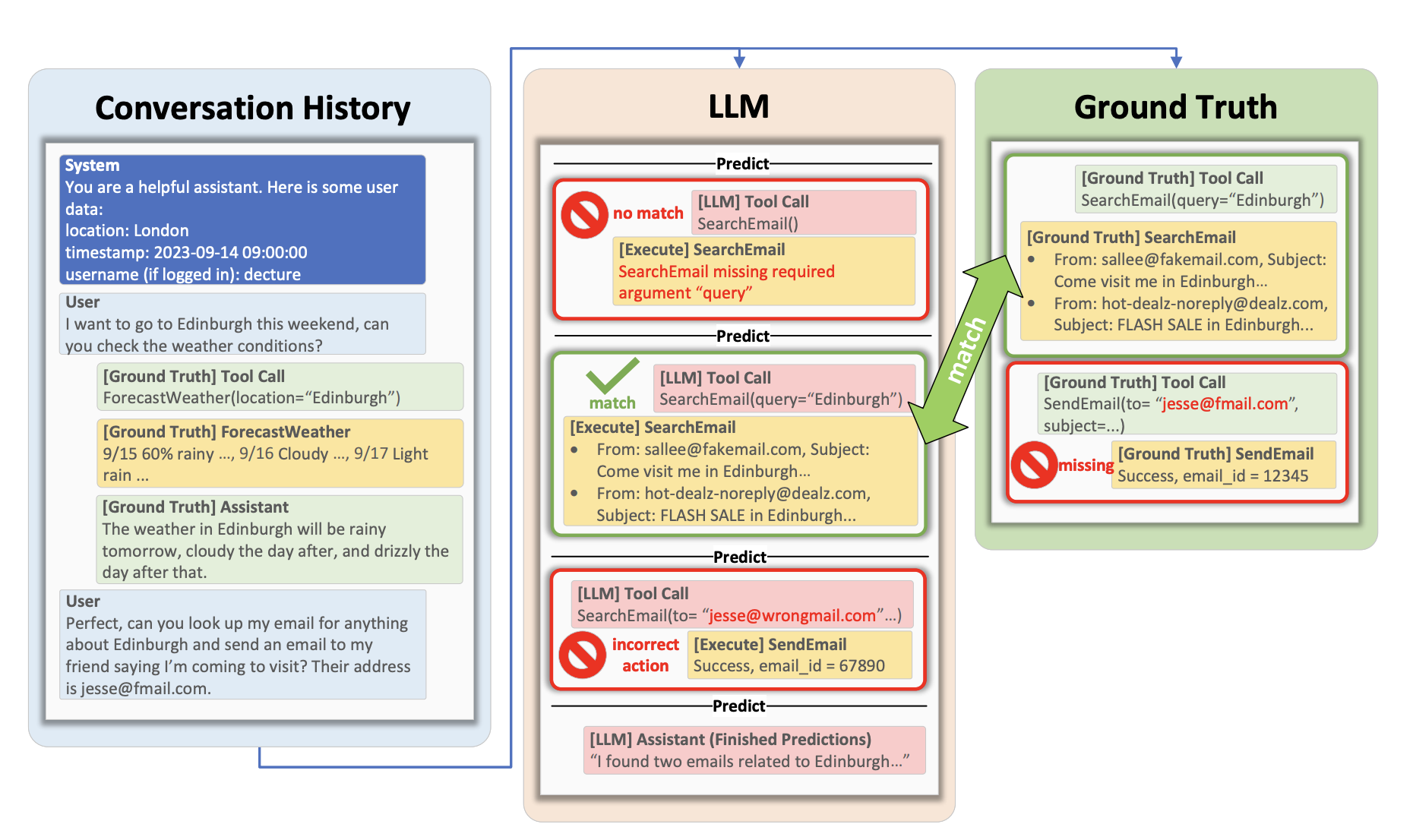
Example:
{
"name": "AccountTools-Calendar-Weather-RegisterUser-0",
"conversation_id": "12b94bad-5896-4282-922b-c51604cd05ef",
"suites_used": [
"AccountTools",
"Calendar"
],
"apis_used": [
"CreateEvent",
"RegisterUser"
],
"scenario": "The user wants to register a new account and create a meeting event with another user. They use RegisterUser to sign up with their username, password, email, name, and phone. They receive a session_token and their account information. They then use QueryUser to search for the username of the other user they want to invite to the meeting. They find the user and use CreateEvent to create a meeting event with the name, description, start_time, end_time, and attendees. They receive an event_id on success. They then use QueryCalendar to check their calendar for any conflicts or overlaps with the new event. They see that there are no conflicts and use CurrentWeather to check the weather of the location where the meeting is to be held. They see that it is sunny and warm.",
"user": {
"username": "hestler",
"email": "j.hester@gahoo.com",
"phone": "708-340-0190",
"name": "Julian Hester",
"password": "Meizuch4uu"
},
"metadata": {
"location": "San Francisco",
"timestamp": "2023-09-11 09:00:00"
},
"conversation": [
{
"index": 0,
"role": "user",
"text": "New employee registers a new account. Then sets up one on one with manager and other members of their team."
},
...
Nexus Function Calling Leaderboard (NFCL, December 5, 2023)
The Nexus Function Calling Benchmark tests models on three main categories:
Single Calls:
Tasks that require only one function call.Parallel Calls:
Tasks that require more than one function, but no function relies on the outputs of other functions.Nested Calls:
Tasks that require more than one function, where the outputs of a function are the inputs to another function.
They use ground truth labels to evaluate the models, and compute an accuracy score using exact match. The model must return exactly the correct tool syntax with the correct inputs. For example, the following input:
Could you please pull the CPE records associated with 'Java' and summarize the first 8 results?
must return exactly the following output:
summarize_cvecpes(searchCPE(keywordSearch='Java', limit=8))
Berkley Function Calling Leaderboard v1 (BFCL v1, March 5, 2024)
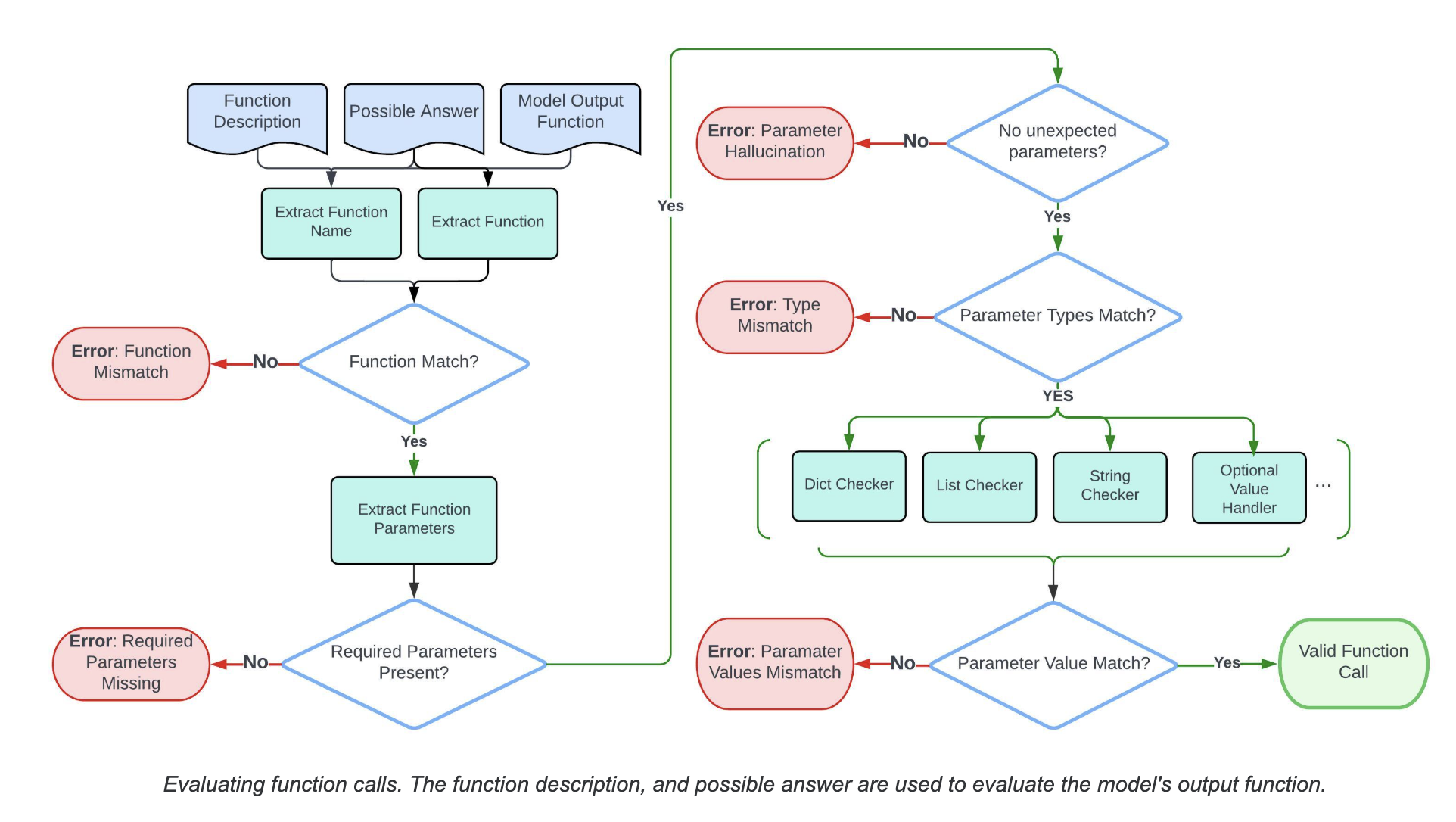
BFCL v1 evaluates single-call tool calling capabilities across two categories: Python and non-Python. The benchmark employs a hierarchical approach combining AST-based and state-based evaluations, where they assess models across multiple dimensions:
- Function Call Generation: Assesses the model’s ability to generate syntactically correct function calls consistent with provided documentation. This includes:
- Correct function name selection
- Proper parameter formatting
- Accurate type validation for parameters
- Appropriate handling of optional parameters
- Parameter Validation: Goes beyond syntactic correctness to thoroughly validate parameters:
- Checks required vs. optional parameter handling
- Strict type validation (
int,float,string,boolean, etc.) - Value validation against expected ranges or formats
- Special handling for language-specific requirements (e.g., Java
HashMap)
- Execution Validation: Confirms actual execution success for executable functions:
- Validates successful function execution
- Ensures correct output types and matches against expected results
- Verifies robust error handling
- Relevance Detection: Measures the model’s ability to correctly identify when a tool call appropriate:
- Detects situations where no function call is needed
- Selects the most relevant function from multiple potential tools
- Prevents hallucinated function calls
BFCL v1 emphasizes strict type checking and parameter validation. For example, it accommodates Python’s implicit type conversion (allowing integers for floats), while Java or JavaScript evaluations enforce strict type matches (e.g., requiring 5.0 rather than 5 for floats).
Evaluation outcomes are calculated using accuracy scores based on ground-truth function calls.
τ-Bench, (June 17, 2024)
τ-bench is a benchmark designed to evaluate how well agents handle tool-augmented interactions in the domains of airline booking and retail over multiple turns.
Each domain includes:
- A policy file detailing domain-specific rules, used to define the correct post-task state.
- A ground truth database with before/after snapshots for each task.
Tasks are grounded in tool use, with each user request typically mapped to a specific tool (e.g., changing a flight, calculating a price), avoiding complex multi-tool reasoning.
Evaluation is based on:
- Whether the final database state matches the ground truth.
- Whether required outputs (like a total price) appear as substrings in the model’s response.
- The pass^k metric, which measures how often a model completes a task successfully over k runs, allowing for evaluation of both accuracy and consistency.
No constraints are imposed on tool choice or order of execution—only on final outcomes.

ToolSandbox, (August 8, 2024)
ToolSandbox takes a slightly different approach to tool calling evaluation by focusing on complex, multi-step tool calling scenarios involving conversational contexts and state dependencies.
The authors utilize two key evaluation concepts: Milestones and Minefields, which help evaluate both successful task completion and error handling.
Milestones: Represent key state transitions that must occur in the correct order.
- Each milestone has a similarity measure (0-1) measuring progress.
- Milestones can have dependencies on other milestones.
- They form a Directed Acyclic Graph (DAG) representing valid execution paths.
Minefields: Represent invalid states or actions that must be avoided.
- Any minefield violation immediately results in a score of 0.
- Used to test an agent’s ability to recognize impossible tasks.
- Helps evaluate model error handling and safety mechanisms.
ToolSandbox employs a composite scoring system that combines:
Column-wise Similarity Functions: Evaluates similarity between expected and actual trajectories of tool calls and system states. Metrics include exact matching (binary states),
ROUGE-L(textual states), AST matching (tool traces), and geometric mean for final aggregation.Milestone Matching: Matches trajectory snapshots to milestone nodes via similarity measures, enforcing correct execution paths through dependency checks and topological ordering.
Interactive Evaluation:
On-policy Assessment:
- Live interaction with LLM user simulator
- Tests handling of ambiguous requests
- Measures dialogue state tracking
Comprehensive Task Completion:
- Evaluates both intermediate and final outcomes
- Assigns partial credit for partial completion
- Tracks turn count as efficiency metric
Example: Consider in which cellular service is initially off, and the user asks to send a text message. The milestones would be:
- Activate cellular service.
- Search contacts.
- Send message with correct arguments.
- Verify the message exists in database with matching phone number and content.
The final evaluation score combines milestone and minefield similarity:
score = scoreM+ × I(scoreM− = 0)
scoreM+is the milestone similarityscoreM−is minefield similarity (zero indicates no violations)
BFCL v2, (August 19, 2024)
BFCL v2 enhances BFCL v1 with two key improvements:
“Live” dataset (user-contributed):
Allows for more dynamic evaluation of tool calling capabilities.Refine relevance detection:
Distinguishes between irrelevance detection (recognizing no tool call is appropriate) and relevance detection (correctly identifying that at least one tool call is appropriate for a given user query).
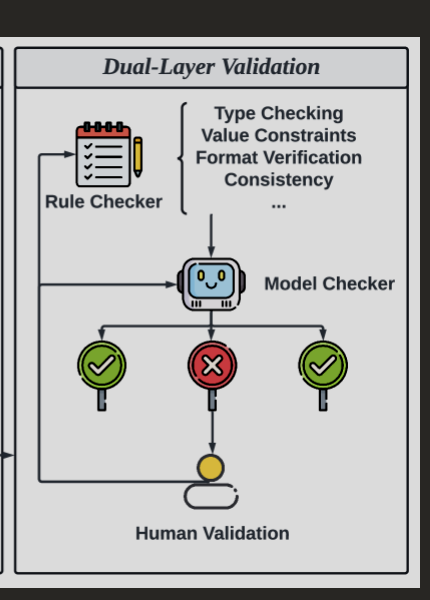
ToolACE, (September 2, 2024)
ToolACE presents a framework for fine-tuning high-quality tool calling models, though they have a fairly comprehensive evaluation section. While not primarily an evaluation paper, it introduces several verification approaches that combine rule-based and model-based methods:
- Rule-based Verification:
For rule-based verification, they use four primary metrics, of which the first two are used for tool calling evaluation, the other two are used for dialogue evaluation and data consistency evaluation. For tool calling evaluation, they use the following methods:
Function Name Validation:
- Checks if the function name is present in the model’s response
- Ensures the function name is correct
- Verifying Executability:
- First, confirm that the API name matches one from the given tool list.
- Second, verify that all required parameters are accurately provided.
- Finally, use regular expressions to ensure that the parameter formats and patterns adhere to those specified in the API documentation.
Verifying API Definition Clarity:
- Check if the API definition complies with JSON Schema specifications.
- Check if the API definition contains all necessary fields.
- Model-based Verification:
For model-based verification, they focus on the following methods:
- Hallucination Detection: Identifies whether the values of input parameters in function calls are fabricated — not mentioned in either the user query or the system prompt.
- Consistency Validation: Verifies that the responses can effectively complete the user’s task and ensures the dialogue content adheres to the constraints and instructions in the user query and system prompt.
- Tool Response Validation: Ensures that the simulated tool responses align with the API definition.
- Relevance Quantification: Uses BGE embeddings and cosine similarity to measure query-API description alignment \
To quantify this relevance, we employ BGE [22] to extract embeddings and utilize cosine similarity to assess the degree of similarity. Let eq and et be the embeddings of the query and the API description, respectively. The complexity is then defined as follows: \
complexity = −cosine_similarity(eq, et).
BFCL v3, (September 19, 2024)
BFCL v3 builds upon previous version by introducing multi-turn tool calling evaluation, shifting from purely AST-based execution-based evaluation to a more comprehensive approach that includes state-based and response-based evaluation. Evaluations occur across three primary dimensions:
Single-turn Evaluation:
Maintains the same metrics as BFCL v1 and v2:- AST-based syntax validation
- Executable function checks
- Relevance detection
State-based Evaluation:
Compares final backend system state after all tool calls:- Focuses on the final state rather than the exact execution path.
- Validates that the end state matches ground truth.
- Allows for multiple valid paths to reach the same final state.
- Excludes private attributes (prefixed with
_) from state comparison.
Response-based Evaluation:
Compares the model’s execution path against predefined minimal viable execution paths:- Ground truth consists of minimal viable execution paths labeled with full context
- Model result is considered correct if it contains the ground truth as a subset
- Allows for additional function calls or different trajectories as long as the essential path is followed
This evalaution approach allows for multiple valid ways to accomplish a task, and the focus is on achieving the correct end state rather than following a specific execution path.
Example of a simple function call from the BFCL v3 dataset:
{
"id": "simple_0",
"question": [
[
{
"role": "user",
"content": "Find the area of a triangle with a base of 10 units and height of 5 units."
}
]
],
"function": [
{
"name": "calculate_triangle_area",
"description": "Calculate the area of a triangle given its base and height.",
"parameters": {
"type": "dict",
"properties": {
"base": {
"type": "integer",
"description": "The base of the triangle."
},
"height": {
"type": "integer",
"description": "The height of the triangle."
},
"unit": {
"type": "string",
"description": "The unit of measure (defaults to 'units' if not specified)"
}
},
"required": [
"base",
"height"
]
}
}
]
}
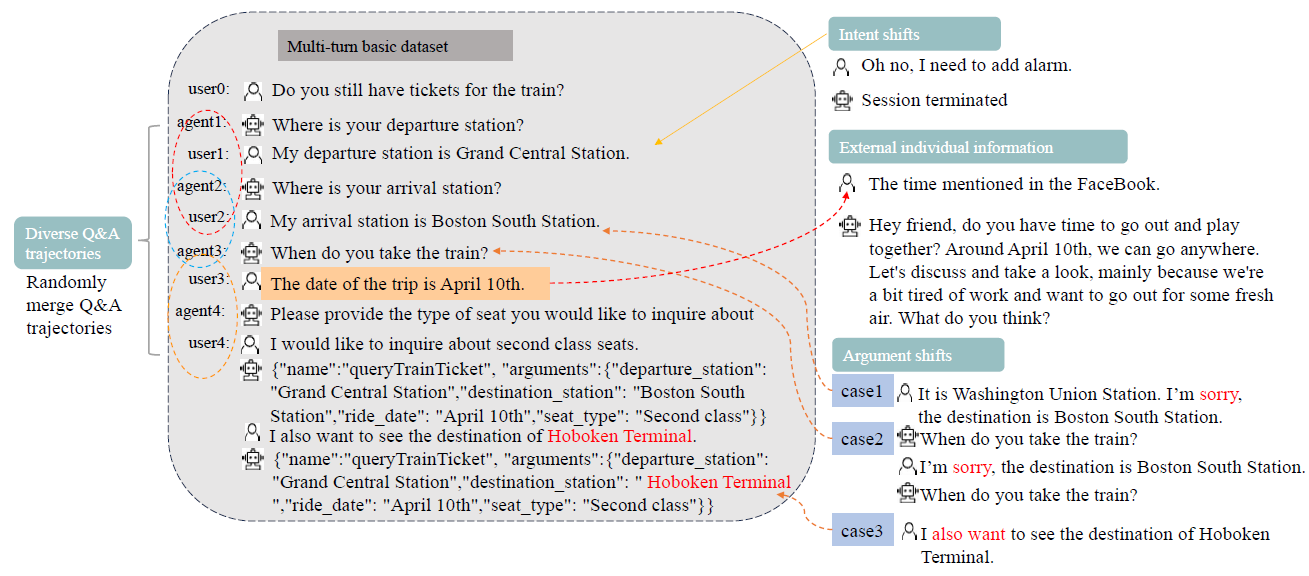
HammerBench, (December 21, 2024)
HammerBench was created to evaluate LLM function-calling capabilities in chat-style interactions that simulate mobile assistant scenarios. They frame their evaluation as single turn and multi-turn scenarios.
- Single-Turn Scenarios:
- Perfect instructions: User query clearly provides all required parameter values
- Imperfect instructions: Query only provides some required parameter values
- External individual information: Query contains pronouns referring to external information
- Irrelevant queries: No appropriate tool in the candidate list can solve the query
- Multi-Turn Scenarios:
- Diverse question-answer trajectories: Varying patterns of interaction (e.g., single question-single answer, multi-question-multi-answer)
- Intent shifts: User changes their intent mid-conversation
- Argument shifts: User modifies slot values before or after tool execution
- External individual information: User answers with pronouns instead of direct values
For measuring performance, HammerBench uses several metrics:
- Accuracy (Acc.): Traditional metric measuring when function and parameter names are all correctly predicted
- Function Name Accuracy (Func. Acc.): Measures accuracy of function names only
- Parameter Hallucination Rate (PHR): Tracks incorrect parameter names
- Parameter Missing Rate (PMR): Tracks missing parameters
- Progress Rate (PR): Measures correct function calls up to the point of error
- Success Rate (SR): Overall accuracy across all turns in a conversation
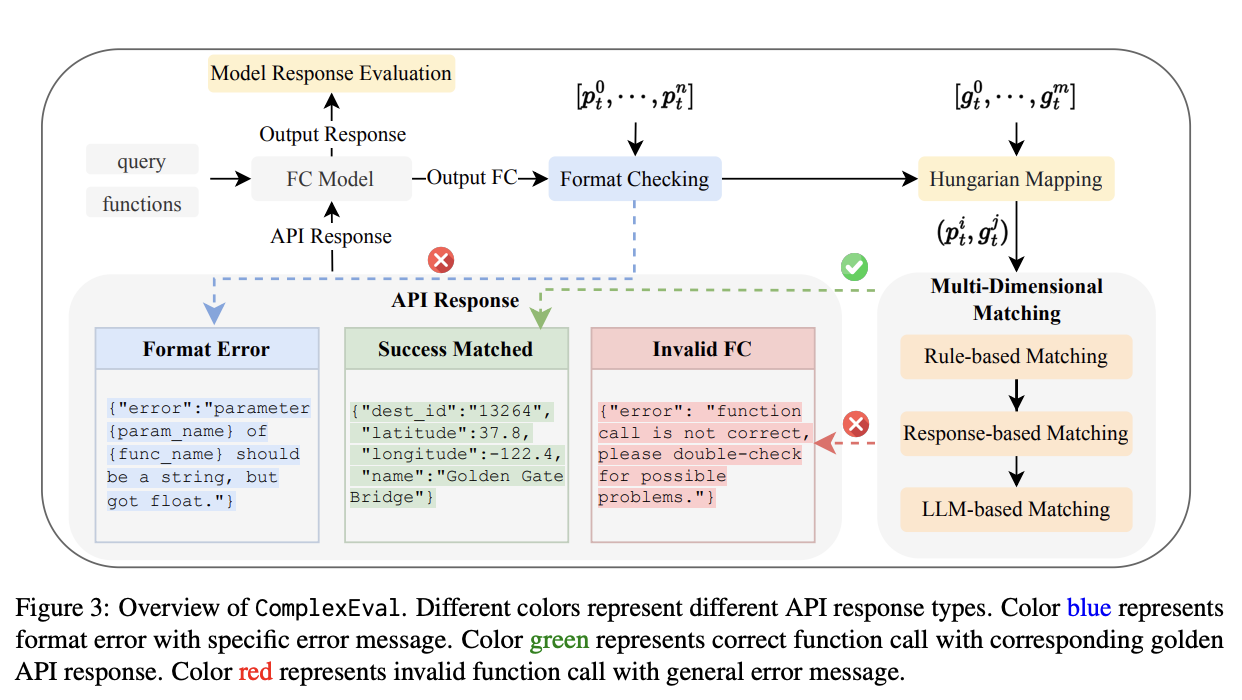
ComplexFuncBench, (January 15, 2025)
The paper introduces ComplexEval, “an automatic evaluation framework specifically designed for complex function calling evaluation”. Their framework combines several different evaluation methods for tool calling, and separate evaluation methods for model responses.
ComplexFuncBench expands other evaluation methods in other papers mentioned above by looking at Parameter Value Reasoning, Long Parameter Values, and Long-Context (128K).
Tool Calling Evaluation: The evaluation process includes format checking, Hungarian mapping for function calls, and multi-dimensional matching: arxiv
- Format Checking This includes three parts:
- Verifying that the called function is in the available function list
- Ensuring all required parameters are included in the call
- Confirming that the type of each parameter meets the requirements in the function description
If a function call fails format checking, a specific error message is returned as the API response. This approach evaluates the model’s self-correction ability
- Hungarian Mapping For function calls with correct formats, the system:
- Uses the
bgelarge-en-v1.5model to obtain text embeddings for each tool call - Concatenates function name and parameters into a single string for text encoding
- Calculates cosine similarity between predicted and golden tool calls
- Employs the Hungarian mapping algorithm to create optimal mappings between predicted and golden tool calls
Imagine you have:
- A set of workers (in this case, predicted tool calls)
- A set of jobs (in this case, golden/correct tool calls)
- Each worker can do each job with a certain efficiency/cost
You want to assign one worker to each job in a way that maximizes overall efficiency or minimizes the total cost.
The authors follow this process:
- Creating Embeddings: First, the system converts each tool call (both predicted and golden ones) into a numerical representation (embedding) using a language model. It does this by combining the function name and its parameters into a text string and then getting the embedding.
- Calculating Similarity: Next, it calculates how similar each predicted tool call is to each golden tool call using cosine similarity between their embeddings.
- Finding Optimal Pairings: The Hungarian algorithm then finds the best overall assignment - which predicted tool call should be matched with which golden tool call - to maximize the total similarity.
- Multi-Dimensional Matching After mapping, the framework uses three matching methods to determine equivalence:
- Rule-based Matching: Determines equivalence through exact matching. Two identical function calls are considered equivalent.
- Response-based Matching: Determines equivalence by comparing the returned API responses. Two function calls are considered equivalent when they return identical results. For example, if the “adults” parameter default value is 1, then Search_Hotel(New_York, adults=1) and Search_Hotel(New_York) are equivalent.
- LLM-based Matching: Leverages GPT-4o to determine equivalence. Parameter values can be expressed in different forms as long as the meaning is the same. For example, “New York” and “NY” are equivalent, as are “Narita International Airport” and “Tokyo Narita International Airport”.
Summary & Trade-offs
Here’s a quick summary of common evaluation methods for tool calling, along with their key strengths and trade-offs. This is not an exhaustive list.
AST-Based Evaluation
The Berkeley Function Calling Leaderboard (BFCL) introduced AST-based evaluation as a core method for evaluating tool calls. This involves:
- Parsing the function call into an an abstract syntax tree (AST)
- Validating the function name matches documentation
- Checking required parameters are present and valid
- Verifying parameter types and values
Strengths:
- Clear pass/fail criteria
- Catches basic syntax and parameter errors
- Easy to automate
Limitations:
- Only validates syntax, not semantic correctness
- Cannot assess if tool use makes sense in context
- Misses state-based errors
State-Based Evaluation
Papers like ToolSandbox introduce state-based evaluation approaches that verify:
- Did tool calls modify system state correctly?
- Were state dependencies handled properly?
- Did the final state match expected outcomes?
This is particularly important for stateful tools like file systems or database operations where the order and dependencies between calls matter.
For example, when evaluating a “send message” task, state-based evaluation would verify:
- Cellular service was enabled first
- Contact was found via search
- Message was sent successfully
- Message exists in message database
Key Insight: The tool calling trajectory is less important than reaching the correct end state. Multiple valid paths may exist.
Response-Based Evaluation
Response-based evaluation focuses on the semantic correctness of tool usage, asking:
- Did the tool call accomplish the user’s intended task?
- Was the tool used appropriately for the task?
- Were the tool’s outputs used correctly?
This approach typically requires comparing model outputs with ground-truth solutions or having expert annotators evaluate tool usage.
Hybrid Approaches
More recent work like BFCL v3 combines multiple evaluation strategies:
Tool Call Evaluation
├── Syntax Validation (AST)
├── State Validation
│ ├── Pre-conditions
│ ├── Post-conditions
│ └── State Dependencies
└── Semantic Validation
├── Intent Fulfillment
└── Tool Usage Quality
Unlike earlier approaches, which focused primarily on single-step tool calling where one user request maps to one tool call, This comprehensive approach provides a more realistic evaluation of complex tool calling behaviors.
Single-Step Evaluation
Papers like API-Bank focus on evaluating:
- Correct tool selection from available options
- Valid parameter construction
- Basic error handling
Multi-Step Evaluation
More recent work like tau-Bench evaluates sequential tool calling:
- Dependencies and correct ordering of multiple tool calls
- State management across steps
- Error recovery and retries
- Completion of complex tasks
Key Insight: Multi-step evaluation mirrors real-world scenarios more closely but requires sophisticated evaluation approaches.
State Management and Dependencies
A critical aspect of tool calling is managing state and dependencies between calls. ToolSandbox uses the concept of “milestones” and “minefields” to evaluate this:
Milestones:
Key state transitions that must occur, such as:
- Preconditions being satisfied
- State changes executed correctly
- Dependencies between calls handled appropriately
Minefields:
Invalid states that must be avoided, such as:
- Illegal state transitions
- Violations of dependencies
- Failed preconditions or incorrect states
For example, milestones for sending a message might be:
- Cellular service enabled
- Contact found
- Message sent
- Message in database
While minefields would include:
- Sending without cellular service
- Using invalid contact info
- Duplicate messages
Recommendations
Based on the literature review, here are our recommendations for builders working with models that use tools (or agents that use tools):
Use multi-dimensional evaluation
- Combine syntax, state, and semantic validation
- Don’t rely solely on basic syntax checking (AST-based)
- Consider both successful and failed cases
Focus on state management:
- Explicitly track state dependencies
- Validate pre- and post-conditions
- Test error recovery
Evaluate complex scenarios:
- Go beyond single-step evaluation
- Include multi-step interactions
- Assess state handling
Measure what matters, such as:
- Task completion rate - whether the model can complete the task
- State correctness - whether the model correctly updates the state
- Error handling - whether the model can handle errors gracefully
- Recovery capabilities - whether the model can recover from errors
- Plan generation and adherence - whether the model can generate and follow a plan
Document limitations
- Note edge cases
- Identify failure modes
- Track known issues
Gaps, Looking Ahead & Discussion
Throughout our research, we observed increasing sophistication in tool calling evaluations. While this progress is promising from a research standpoint, it underscores the growing burden on product teams. Understanding evaluation trade-offs, required investments, and practical limitations is critical for effective deployment.
As agentic systems become more complex and their operating environments grow richer, teams must similarly evolve evaluation setups to reflect real-world production conditions and inherent uncertainties accurately.
The field of LLM tool calling evaluation is evolving rapidly, yet significant gaps remain. In our review, several critical areas stood out as underserved or entirely missing from current approaches:
- Interactive vs. Single-turn Task Completion
A critical open question we identified is whether interactive task completion (chat-style, multi-turn), where models engage step-by-step with a user in a conversational setting, is inherently more challenging than single-turn asynchronous execution, where models independently complete tasks without intermediate feedback, assuming equivalent resources and execution time.
Surprisingly, none of the literature we found explicitly compares these two scenarios, despite their practical significance. Clarifying this distinction matters because it directly influences:
- Agent Design: Whether you build interactive conversational agents or autonomous, asynchronous agents.
- Task Suitability: Which tasks your models can reliably handle.
- Evaluation Methods: Which evaluation approaches (e.g., chat-based vs. asynchronous trajectory evaluation) are most appropriate for your use case.
- Reference-free Evaluation Methods
Current approaches heavily rely on ground-truth annotations or references. There is a lack of robust evaluation methods that operate entirely reference-free (expert annotations). Some methods use similarity checks or basic hallucination detection heuristics (like checking whether parameters appear explicitly in prompts), but these approaches tend to be superficial and limited.
Developing robust reference-free evaluation techniques would reduce dependence on manual annotations and help scale evaluations more effectively.
Ground-truth Acquisition & Data Curation
Another significant gap is how to systematically acquire reliable ground truth data without constant manual labeling. Nearly all current methods explicitly gather high-quality, human-labeled reference data. There’s a clear need for new data-curation methods or automated strategies to reliably generate or approximate ground truths based on real production trajectories, enabling more scalable and efficient evaluation workflows.Planning and Plan Adherence
Almost none of the reviewed papers thoroughly addressed the role of explicit planning or plan adherence in evaluation. Specifically, we see a gap in methods that assess:
- Whether models explicitly generate an correct initial plan given the user query.
- How well models adhere to these plans during task execution.
Without evaluating plan generation and plan adherence, we overlook a critical aspect of tool-calling agents, particularly in complex or multi-step scenarios.
Finally, throughout our research, we observed increasing sophistication in tool calling evaluations. While this progress is promising from a research standpoint, it underscores the growing burden on product teams. Understanding evaluation trade-offs, required investments, and practical limitations is critical for effective deployment.
As agentic systems become more complex and their operating environments grow richer, teams must similarly evolve evaluation setups to reflect real-world production conditions and inherent uncertainties accurately.
👋
Thanks for reading! We’d love to hear about your experiences using or evaluating tool calling capabilities in your models and agents. Did we miss an important approach, or do you have insights from your own projects to share? What other literature should we be looking at?
Let Freddie know on X @freddie_v4 or email at freddie@quotientai.co.
References
Li, Minghao, et al. API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs. 2023, https://arxiv.org/abs/2304.08244.
Farn, Nicholas, and Richard Shin. ToolTalk: Evaluating Tool-Usage in a Conversational Setting. 2023, https://arxiv.org/abs/2311.10775.
Nexusflow. Introducing NexusRaven-V2: Surpassing GPT-4 for Zero-shot Function Calling. 2023, https://nexusflow.ai/blogs/ravenv2.
Yan, Fanjia, et al. Berkeley Function Calling Leaderboard (BFCL) v1. 2024, https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html.
Yao, Shunyu, et al. τ-Bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. 2024, https://arxiv.org/abs/2406.12045.
Patil, Shishir G., et al. BFCL v2: Live Dataset. 2024, https://gorilla.cs.berkeley.edu/blogs/12_bfcl_v2_live.html.
Liu, Weiwen, et al. ToolACE: Winning the Points of LLM Function Calling. 2024, https://arxiv.org/abs/2409.00920.
Mao, Huanzhi, et al. BFCL v3: Multi-Turn & Multi-Step Function Calling. 2024, https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html.
Wang, Jun, et al. HammerBench: Fine-Grained Function-Calling Evaluation in Real Mobile Device Scenarios. 2024, https://arxiv.org/abs/2412.16516.
Lu, Jiarui, et al. ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities. 2024, https://arxiv.org/abs/2408.04682.
Zhong, Lucen, et al. ComplexFuncBench: Exploring Multi-Step and Constrained Function Calling under Long-Context Scenario. 2025, https://arxiv.org/abs/2501.10132.