
Introduction
If you’re building AI agents that interact with external tools and APIs, you know that tool calls are both essential and error-prone. Even when your agent’s reasoning looks perfect, the actual API calls can fail in subtle ways - wrong endpoints, malformed parameters, or incorrect data types. These issues are particularly challenging because they’re often hidden behind seemingly reasonable responses.
As developers, we need better tools for evaluating these tool calls. Traditional testing approaches fall short because agent behavior is non-deterministic - the same prompt can generate different tool calls each time. We need a systematic way to:
- Evaluate if tool calls match their schema definitions
- Identify patterns in tool selection and parameter errors
- Compare tool call accuracy across different agents
limbic is our system for capturing, understanding, and improving agent behavior. For tool use evaluation specifically, we’ve developed the limbic-tool-use models that analyze tool calls to detect issues like wrong tool selection, incorrect parameter names, and malformed values. Think of it as an automated way to catch tool use errors before they impact your users.
In this guide, we’ll:
- Walk through common tool call failure patterns with code examples
- Show how to use
limbic-tool-use-7B-32Kto catch these issues - Share practical tips for making your agents more reliable
- Provide evaluation code you can run on your own agents
Common Tool Call Failures: A Developer’s Guide
When building AI agents, tool call failures typically fall into three categories. Here’s what they look like in practice:
# 1. Correct Tool Call
{
"name": "search_contacts",
"parameters": {
"name": "John Smith",
"limit": 5
}
}
# 2. Incorrect Tool Selection
{
"name": "find_person", # ❌ Tool doesn't exist
"parameters": {
"name": "John Smith"
}
}
# 3. Incorrect Parameter Names
{
"name": "search_contacts",
"parameters": {
"name": "John Smith", # ❌ Should be "query"
"max_results": 5 # ❌ Should be "limit"
}
}
# 4. Incorrect Parameter Values
{
"name": "search_contacts",
"parameters": {
"query": ["John", "Smith"], # ❌ Should be string
"limit": "5" # ❌ Should be integer
}
}
Each error type that limbic-tool-use identifies suggests different improvements you can make:
- Wrong Tool: If your agent picks the wrong tools, review your tool descriptions and function names. Are they clear and distinct?
- Wrong Names: If parameter names don’t match, check your schema documentation. Are parameter names consistent across similar tools?
- Wrong Values: If values have wrong types or formats, add clear examples and format specifications to your schemas.
Using limbic-tool-use in Your Development Workflow
Let’s walk through how to use limbic-tool-use to catch tool call issues in your agent. Consider this real-world example:
User request: “Schedule a meeting with Jane next week about the new Acme project. Include the notes from our last planning session.”
The agent has access to three tools:
# Tool schemas
tools = {
"search_contacts": {
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string"}
},
"required": ["name"]
}
},
"schedule_event": {
"parameters": {
"type": "object",
"properties": {
"date": {
"type": "string",
"format": "date",
"description": "YYYY-MM-DD format"
},
"participants": {"type": "array"},
"location": {"type": "string"}
},
"required": ["date", "participants"]
}
},
"get_document": {
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
}
}
# Agent's tool calls
agent_calls = [
{
"name": "search_contacts",
"parameters": {"name": "Jane"}
},
{
"name": "schedule_event",
"parameters": {
"date": "next Tuesday", # ❌ Wrong format
"participants": "Jane" # ❌ Should be array
}
},
{
"name": "get_document",
"parameters": {"query": "Acme planning notes"}
}
]
limbic-tool-use’s evaluation reveals:
[
{ "tool_call": "search_contacts", "score": "correct" },
{
"tool_call": "schedule_event",
"score": "incorrect_parameter_values",
"reason": [
"date: must match format YYYY-MM-DD",
"participants: must be array"
]
},
{ "tool_call": "get_document", "score": "correct" }
]
At a glance, the run looks fine: Jane was found, an event was scheduled, notes were retrieved. But limbic-tool-use catches two critical issues that would cause runtime errors:
- The date “next Tuesday” doesn’t match the required
YYYY-MM-DDformat - The participants field is a string instead of the required array
Without limbic-tool-use, these might only surface in production when the calendar API rejects the call. With limbic-tool-use, you catch them during development and ongoing monitor for them in production.
The Dataset
While individual examples are informative, they don’t tell us how frequent each type of failure is. To answer that question and enable systematic evaluation of tool use, we created a comprehensive dataset of 1,000 evaluation cases, available on HuggingFace. Each case consists of:
- A user request in natural language
- A set of available tools with schemas
We evaluate how different models handle these requests, looking at both their tool selection and parameter handling.
For example, a dataset entry looks like this (simplified):
{
"tool_parameters": {
"location": "San Francisco",
"unit": "fahrenheit"
},
"user_prompt": "What's the weather like in San Francisco today? I need to know if I should bring a jacket.",
"system_prompt": "The user is planning their day in San Francisco and needs current weather information to make clothing decisions."
},
"available_tools": [
{
"name": "get_weather",
"description": "Get current weather information for a specified location\n\nReturns temperature, conditions, and forecast\n\nParameters:\n- location: City name or coordinates (required)\n- unit: Temperature unit - 'celsius' or 'fahrenheit' (optional, default: celsius)",
"inputSchema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name or coordinates"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit"
],
"default": "celsius"
}
},
"required": [
"location"
]
}
}
]
You can find the complete dataset and evaluation code in our cookbook.
Evaluation Setup
We used this dataset to test two models: Kimi-K2 and Qwen-235B. The workflow was:
- Run each model on the 1,000 test prompts to generate tool calls.
- Collect their tool call outputs and feed outputs into
limbic-tool-usebic, along with tool schemas and conversation context. - Collect
limbic-tool-use’s structured judgments (correct,incorrect_tool,incorrect_parameter_names,incorrect_parameter_values). - Aggregate results into model-level accuracy, error distributions, failure rates, and per-test breakdowns.
This setup is deliberately lightweight but it shows how limbic-tool-use could be applied in practice: capturing traces, passing them to the evaluator, and using structured verdicts to pinpoint weak spots.
Results
Our evaluation of 1,000 test cases revealed several key patterns in how models handle tool use:
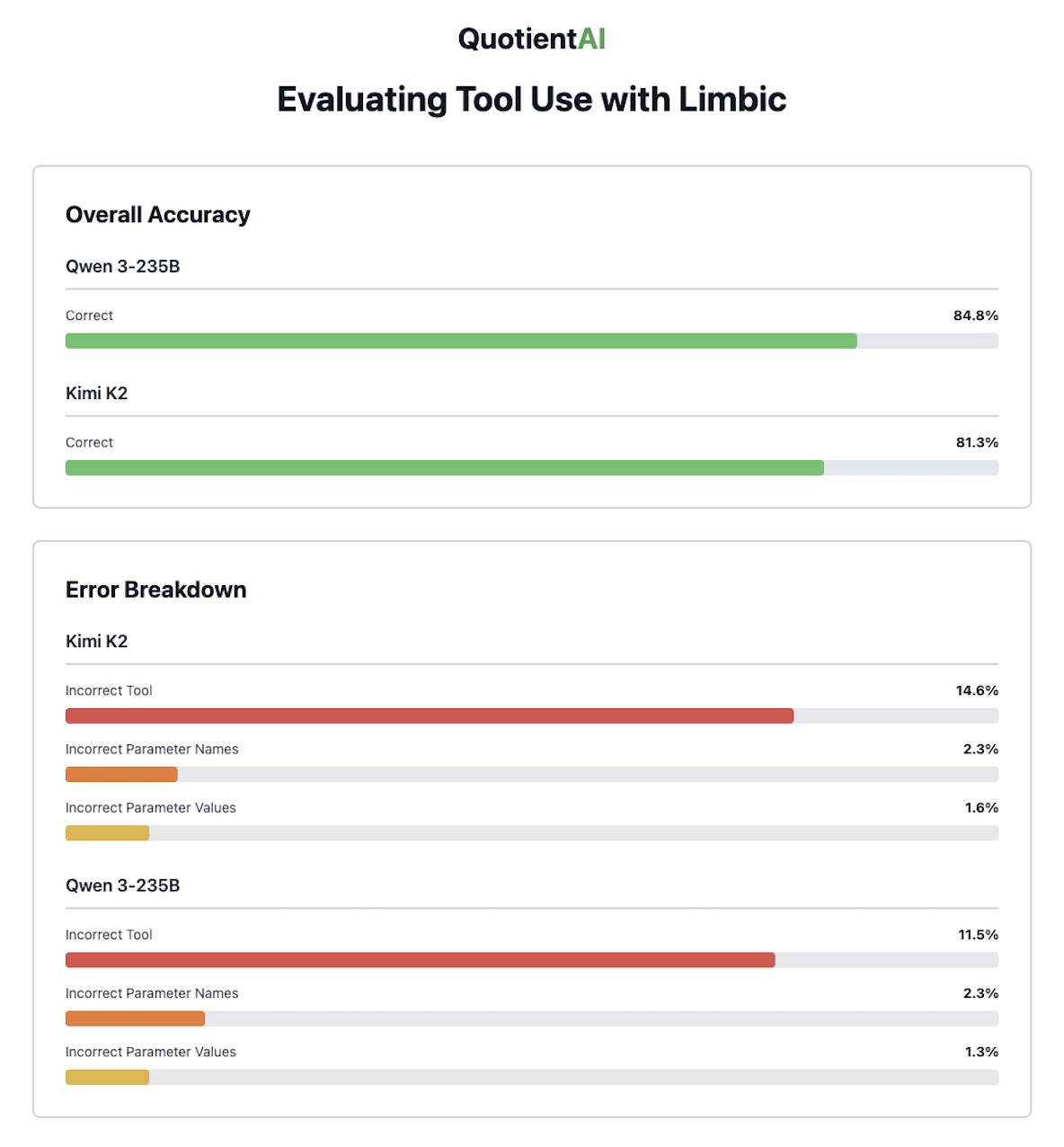
Model Performance Overview:
- Qwen-235B shows better overall performance with 84.9% accuracy (vs Kimi-K2’s 81.5%)
- Tool selection errors are the main challenge (11-15% of all calls)
- Parameter errors are relatively rare:
- Name errors: 2-3% of calls
- Value errors: 1-2% of calls
Null Response Analysis:
- Both models frequently choose not to call tools:
- Kimi-K2: 44.6% null response rate
- Qwen-235B: 35.1% null response rate
- Most of these decisions (87%) correctly identify cases where no tool is needed
- Both models frequently choose not to call tools:
Areas for Improvement:
- Model Development: Focus on tool selection accuracy
- Tool Design: Need clearer descriptions and consistent parameter naming
- Evaluation: Add more edge cases and multi-tool scenarios
These findings suggest that while parameter handling is largely solved, tool selection remains a key challenge. The high rate of correct null responses also shows models can effectively identify when not to use tools.
Common failure patterns include:
- Tool Selection: Models struggle most with ambiguous or overlapping functions (e.g., choosing between similar search tools)
- Parameter Values: Format errors like
"date='next Tuesday'"instead ofYYYY-MM-DD - Parameter Names: Inconsistent naming across similar tools (e.g.,
queryvssearch_term)
The larger point is that surface-level correctness - “the answer looks fine” cannot be trusted. Subtle mismatches in tool choice or parameters accumulate, degrading reliability in ways invisible without tool-level evaluation. limbic-tool-use provides exactly this lens.
Conclusion
Agents succeed or fail not only on reasoning, but on the precision of their tool use. Wrong tools, malformed values, and schema mismatches undermine reliability in ways that final answers alone cannot reveal.
By classifying tool-use errors and surfacing them at scale, limbic-tool-use exposes key patterns in agent behavior. While parameter handling appears largely solved (with errors in 2-3% of cases), tool selection remains the primary challenge (11-15% error rate). This suggests that improving tool descriptions and adding disambiguation hints might be more valuable than focusing on parameter validation.
As agents take on more complex workflows, this kind of systematic evaluation becomes essential. The difference between a plausible assistant and a trustworthy one often lies in understanding not just when to use tools, but also when not to - and limbic-tool-use helps measure both.